Merge pull request 'dev to main periodic update' (#71) from development into main
Reviewed-on: #71
This commit was merged in pull request #71.
This commit is contained in:
@@ -39,15 +39,15 @@ flag. Otherwise exits with code 0. Note that errors set as --warnings will alway
|
||||
### With Python
|
||||
|
||||
* Clone the repository
|
||||
* ```
|
||||
```
|
||||
git clone https://github.com/threefoldfoundation/website-link-checker
|
||||
```
|
||||
* Change directory
|
||||
* ```
|
||||
```
|
||||
cd website-link-checker
|
||||
```
|
||||
* Run the program
|
||||
* ```
|
||||
```
|
||||
python website-link-checker.py https://example.com -e 404 -w all
|
||||
```
|
||||
|
||||
|
||||
@@ -68,16 +68,16 @@ To do so, you simply need to clone the forked repository on your local computer
|
||||
The steps are the following:
|
||||
|
||||
* In the terminal, write the following line to clone the forked `info_grid` repository:
|
||||
* ```
|
||||
```
|
||||
git clone https://github.com/YOUR_GIT_ACCOUNT/info_grid
|
||||
```
|
||||
* make sure to write your own Github account in the URL
|
||||
* To deploy the mdbook locally, first go to the **info_grid** directory:
|
||||
* ```
|
||||
```
|
||||
cd info_grid
|
||||
```
|
||||
* Then write the following line. It will open the manual automatically.
|
||||
* ```
|
||||
```
|
||||
mdbook serve -o
|
||||
```
|
||||
* Note that, by default, the URL is the following, using port `3000`, `http://localhost:3000/`
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
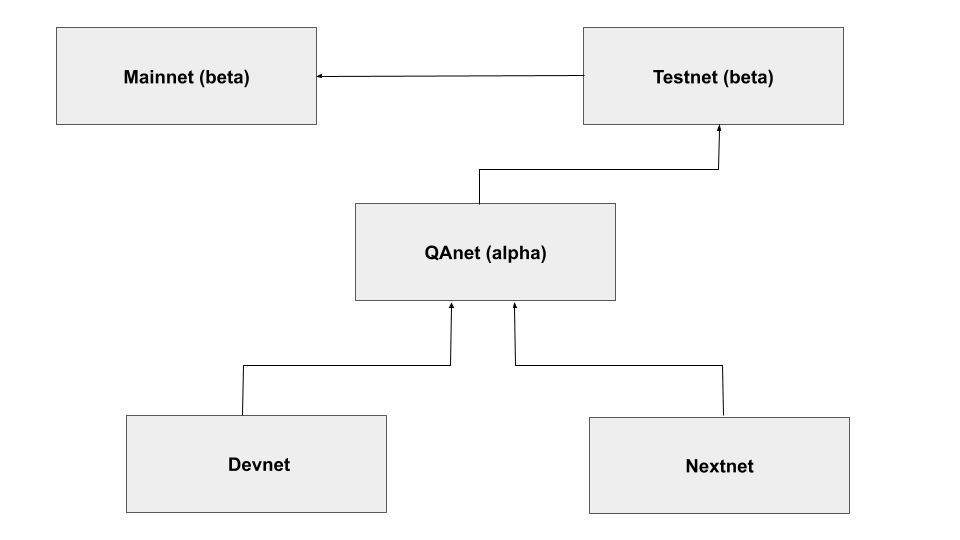
The development cycle is explained below:
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
BIN
collections/collaboration/img/dev_cycle.png
Normal file
BIN
collections/collaboration/img/dev_cycle.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 24 KiB |
@@ -223,27 +223,27 @@ You now have access to the Docker Hub from your local computer. We will then pro
|
||||
* Make sure the Docker Daemon is running
|
||||
* Build the docker container
|
||||
* Template:
|
||||
* ```
|
||||
docker build -t <docker_username>/<docker_repo_name> .
|
||||
```
|
||||
```
|
||||
docker build -t <docker_username>/<docker_repo_name> .
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
docker build -t username/debian12 .
|
||||
```
|
||||
```
|
||||
docker build -t username/debian12 .
|
||||
```
|
||||
* Push the docker container to the [Docker Hub](https://hub.docker.com/)
|
||||
* Template:
|
||||
* ```
|
||||
docker push <your_username>/<docker_repo_name>
|
||||
```
|
||||
```
|
||||
docker push <your_username>/<docker_repo_name>
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
docker push username/debian12
|
||||
```
|
||||
```
|
||||
docker push username/debian12
|
||||
```
|
||||
* You should now see your docker image on the [Docker Hub](https://hub.docker.com/) when you go into the menu option `My Profile`.
|
||||
* Note that you can access this link quickly with the following template:
|
||||
* ```
|
||||
https://hub.docker.com/u/<account_name>
|
||||
```
|
||||
```
|
||||
https://hub.docker.com/u/<account_name>
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -265,13 +265,13 @@ We will now convert the Docker image into a Zero-OS flist. This part is so easy
|
||||
* Under `Name`, you will see all your available flists.
|
||||
* Right-click on the flist you want and select `Copy Clean Link`. This URL will be used when deploying on the ThreeFold Playground. We show below the template and an example of what the flist URL looks like.
|
||||
* Template:
|
||||
* ```
|
||||
https://hub.grid.tf/<3BOT_name.3bot>/<docker_username>-<docker_image_name>-<tagname>.flist
|
||||
```
|
||||
```
|
||||
https://hub.grid.tf/<3BOT_name.3bot>/<docker_username>-<docker_image_name>-<tagname>.flist
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
https://hub.grid.tf/idrnd.3bot/username-debian12-latest.flist
|
||||
```
|
||||
```
|
||||
https://hub.grid.tf/idrnd.3bot/username-debian12-latest.flist
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -283,16 +283,14 @@ We will now convert the Docker image into a Zero-OS flist. This part is so easy
|
||||
* Choose your parameters (name, VM specs, etc.).
|
||||
* Under `flist`, paste the Debian flist from the TF Hub you copied previously.
|
||||
* Make sure the entrypoint is as follows:
|
||||
* ```
|
||||
/sbin/zinit init
|
||||
```
|
||||
```
|
||||
/sbin/zinit init
|
||||
```
|
||||
* Choose a 3Node to deploy on
|
||||
* Click `Deploy`
|
||||
|
||||
That's it! You can now SSH into your Debian deployment and change the world one line of code at a time!
|
||||
|
||||
*
|
||||
|
||||
## Conclusion
|
||||
|
||||
In this case study, we've seen the overall process of creating a new flist to deploy a Debian workload on a Micro VM on the ThreeFold Playground.
|
||||
|
||||
@@ -616,25 +616,25 @@ You now have access to the Docker Hub from your local computer. We will then pro
|
||||
* Make sure the Docker Daemon is running
|
||||
* Build the docker container (note that, while the tag is optional, it can help to track different versions)
|
||||
* Template:
|
||||
* ```
|
||||
```
|
||||
docker build -t <docker_username>/<docker_repo_name>:<tag> .
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
```
|
||||
docker build -t dockerhubuser/nextcloudaio .
|
||||
```
|
||||
* Push the docker container to the [Docker Hub](https://hub.docker.com/)
|
||||
* Template:
|
||||
* ```
|
||||
```
|
||||
docker push <your_username>/<docker_repo_name>
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
```
|
||||
docker push dockerhubuser/nextcloudaio
|
||||
```
|
||||
* You should now see your docker image on the [Docker Hub](https://hub.docker.com/) when you go into the menu option `My Profile`.
|
||||
* Note that you can access this link quickly with the following template:
|
||||
* ```
|
||||
```
|
||||
https://hub.docker.com/u/<account_name>
|
||||
```
|
||||
|
||||
@@ -656,11 +656,11 @@ We will now convert the Docker image into a Zero-OS flist.
|
||||
* Under `Name`, you will see all your available flists.
|
||||
* Right-click on the flist you want and select `Copy Clean Link`. This URL will be used when deploying on the ThreeFold Playground. We show below the template and an example of what the flist URL looks like.
|
||||
* Template:
|
||||
* ```
|
||||
```
|
||||
https://hub.grid.tf/<3BOT_name.3bot>/<docker_username>-<docker_image_name>-<tagname>.flist
|
||||
```
|
||||
* Example:
|
||||
* ```
|
||||
```
|
||||
threefoldtech-nextcloudaio-latest.flist
|
||||
```
|
||||
|
||||
@@ -833,19 +833,20 @@ output "fqdn" {
|
||||
We now deploy Nextcloud with Terraform. Make sure that you are in the correct folder containing the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
terraform init
|
||||
```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy Nextcloud:
|
||||
* ```
|
||||
terraform apply
|
||||
```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
Note that, at any moment, if you want to see the information on your Terraform deployment, write the following:
|
||||
* ```
|
||||
terraform show
|
||||
```
|
||||
|
||||
```
|
||||
terraform show
|
||||
```
|
||||
|
||||
## Nextcloud Setup
|
||||
|
||||
|
||||
@@ -118,25 +118,25 @@ See example below.
|
||||
|
||||
The main template to request information from the API is the following:
|
||||
|
||||
```bash
|
||||
```
|
||||
curl -H "Authorization: bearer <API_token>" https://hub.grid.tf/api/flist/me/<flist_name> -X <COMMAND>
|
||||
```
|
||||
|
||||
For example, if we take the command `DELETE` of the previous section and we want to delete the flist `example-latest.flist` with the API Token `abc12`, we would write the following line:
|
||||
|
||||
```bash
|
||||
```
|
||||
curl -H "Authorization: bearer abc12" https://hub.grid.tf/api/flist/me/example-latest.flist -X DELETE
|
||||
```
|
||||
|
||||
As another template example, if we wanted to rename the flist `current-name-latest.flist` to `new-name-latest.flist`, we would use the following template:
|
||||
|
||||
```bash
|
||||
```
|
||||
curl -H "Authorization: bearer <API_token>" https://hub.grid.tf/api/flist/me/<current_flist_name>/rename/<new_flist_name> -X GET
|
||||
```
|
||||
|
||||
To upload an flist to the ZOS Hub, you would use the following template:
|
||||
|
||||
```bash
|
||||
```
|
||||
curl -H "Authorization: bearer <API_Token>" -X POST -F file=@my-local-archive.tar.gz \
|
||||
https://hub.grid.tf/api/flist/me/upload
|
||||
```
|
||||
@@ -22,19 +22,19 @@ Make sure that you have at least Go 1.19 installed on your machine.
|
||||
## Steps
|
||||
|
||||
* Create a new directory
|
||||
* ```bash
|
||||
```bash
|
||||
mkdir tf_go_client
|
||||
```
|
||||
* Change directory
|
||||
* ```bash
|
||||
```bash
|
||||
cd tf_go_client
|
||||
```
|
||||
* Creates a **go.mod** file to track the code's dependencies
|
||||
* ```bash
|
||||
```bash
|
||||
go mod init main
|
||||
```
|
||||
* Install the Grid3 Go Client
|
||||
* ```bash
|
||||
```bash
|
||||
go get github.com/threefoldtech/tfgrid-sdk-go/grid-client
|
||||
```
|
||||
|
||||
|
||||
@@ -64,83 +64,83 @@ You can use the start script to start all services and then set a cron job to ex
|
||||
You can set a cron job to execute a script running rsync to create the snapshots and generate logs at a given interval.
|
||||
|
||||
- First download the script.
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/create_snapshot.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/create_snapshot.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/create_snapshot.sh
|
||||
```
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/create_snapshot.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/create_snapshot.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/create_snapshot.sh
|
||||
```
|
||||
- Set the permissions of the script
|
||||
```
|
||||
chmod +x create_snapshot.sh
|
||||
```
|
||||
```
|
||||
chmod +x create_snapshot.sh
|
||||
```
|
||||
- Make sure to a adjust the snapshot creation script for your specific deployment
|
||||
- Set a cron job
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
- Here is an example of a cron job where we execute the script every day at 1 AM and send the logs to `/var/log/snapshots/snapshots-cron.log`.
|
||||
```sh
|
||||
0 1 * * * sh /opt/snapshots/create-snapshot.sh > /var/log/snapshots/snapshots-cron.log 2>&1
|
||||
```
|
||||
```sh
|
||||
0 1 * * * sh /opt/snapshots/create-snapshot.sh > /var/log/snapshots/snapshots-cron.log 2>&1
|
||||
```
|
||||
|
||||
### Start All the Services
|
||||
|
||||
You can start all services by running the provided scripts.
|
||||
|
||||
- Download the script.
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/startall.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/startall.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/startall.sh
|
||||
```
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/startall.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/startall.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/startall.sh
|
||||
```
|
||||
- Set the permissions of the script
|
||||
```
|
||||
chmod +x startall.sh
|
||||
```
|
||||
```
|
||||
chmod +x startall.sh
|
||||
```
|
||||
- Run the script to start all services via docker engine.
|
||||
```
|
||||
./startall.sh
|
||||
```
|
||||
```
|
||||
./startall.sh
|
||||
```
|
||||
|
||||
### Stop All the Services
|
||||
|
||||
You can stop all services by running the provided scripts.
|
||||
|
||||
- Download the script.
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/stopall.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/stopall.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/stopall.sh
|
||||
```
|
||||
- Main net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/mainnet/stopall.sh
|
||||
```
|
||||
- Test net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/testnet/stopall.sh
|
||||
```
|
||||
- Dev net
|
||||
```
|
||||
wget https://github.com/threefoldtech/grid_deployment/blob/development/grid-snapshots/devnet/stopall.sh
|
||||
```
|
||||
- Set the permissions of the script
|
||||
```
|
||||
chmod +x stopall.sh
|
||||
```
|
||||
```
|
||||
chmod +x stopall.sh
|
||||
```
|
||||
- Run the script to stop all services via docker engine.
|
||||
```
|
||||
./stopall.sh
|
||||
```
|
||||
```
|
||||
./stopall.sh
|
||||
```
|
||||
|
||||
## Expose the Snapshots with Rsync
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@ We present in this section of the developers book a partial list of system compo
|
||||
|
||||
<h2> Table of Contents </h2>
|
||||
|
||||
- [Reliable Message Bus (RMB)](rmb_toc.md)
|
||||
- [Reliable Message Bus - RMB](rmb_toc.md)
|
||||
- [Introduction to RMB](rmb_intro.md)
|
||||
- [RMB Specs](rmb_specs.md)
|
||||
- [RMB Peer](peer.md)
|
||||
|
||||
@@ -14,7 +14,7 @@
|
||||
- [Building](#building)
|
||||
- [Running tests](#running-tests)
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
## What is RMB
|
||||
|
||||
@@ -27,7 +27,7 @@ Out of the box RMB provides the following:
|
||||
- Support for 3rd party hosted relays. Anyone can host a relay and people can use it safely since there is no way messages can be inspected while using e2e. That's similar to `home` servers by `matrix`
|
||||
|
||||

|
||||
***
|
||||
|
||||
## Why
|
||||
|
||||
RMB is developed by ThreefoldTech to create a global network of nodes that are available to host capacity. Each node will act like a single bot where you can ask to host your capacity. This enforced a unique set of requirements:
|
||||
@@ -45,17 +45,17 @@ Starting from this we came up with a more detailed requirements:
|
||||
- Then each message then can be signed by the `bot` keys, hence make it easy to verify the identity of the sender of a message. This is done both ways.
|
||||
- To support federation (using 3rd party relays) we needed to add e2e encryption to make sure messages that are surfing the public internet can't be sniffed
|
||||
- e2e encryption is done by deriving an encryption key from the same identity seed, and share the public key on `tfchain` hence it's available to everyone to use
|
||||
***
|
||||
|
||||
## Specifications
|
||||
|
||||
For details about protocol itself please check the [specs](rmb_specs.md).
|
||||
***
|
||||
|
||||
## How to Use RMB
|
||||
|
||||
There are many ways to use `rmb` because it was built for `bots` and software to communicate. Hence, there is no mobile app for it for example, but instead a set of libraries where you can use to connect to the network, make chitchats with other bots then exit.
|
||||
|
||||
Or you can keep the connection forever to answer other bots requests if you are providing a service.
|
||||
***
|
||||
|
||||
## Libraries
|
||||
|
||||
If there is a library in your preferred language, then you are in luck! Simply follow the library documentations to implement a service bot, or to make requests to other bots.
|
||||
@@ -64,14 +64,14 @@ If there is a library in your preferred language, then you are in luck! Simply f
|
||||
|
||||
- Golang [rmb-sdk-go](https://github.com/threefoldtech/rmb-sdk-go)
|
||||
- Typescript [rmb-sdk-ts](https://github.com/threefoldtech/rmb-sdk-ts)
|
||||
***
|
||||
|
||||
### No Known Libraries
|
||||
|
||||
If there are no library in your preferred language, here's what you can do:
|
||||
|
||||
- Implement a library in your preferred language
|
||||
- If it's too much to do all the signing, verification, e2e in your language then use `rmb-peer`
|
||||
***
|
||||
|
||||
## What is rmb-peer
|
||||
|
||||
think of `rmb-peer` as a gateway that stands between you and the `relay`. `rmb-peer` uses your mnemonics (your identity secret key) to assume your identity and it connects to the relay on your behalf, it maintains the connection forever and takes care of
|
||||
@@ -85,11 +85,11 @@ Then it provide a simple (plain-text) api over `redis`. means to send messages (
|
||||
|
||||
> More details can be found [here](rmb_specs.md)
|
||||
|
||||
***
|
||||
|
||||
## Download
|
||||
|
||||
Please check the latest [releases](https://github.com/threefoldtech/rmb-rs/releases) normally you only need the `rmb-peer` binary, unless you want to host your own relay.
|
||||
***
|
||||
|
||||
## Building
|
||||
|
||||
```bash
|
||||
@@ -97,7 +97,7 @@ git clone git@github.com:threefoldtech/rmb-rs.git
|
||||
cd rmb-rs
|
||||
cargo build --release --target=x86_64-unknown-linux-musl
|
||||
```
|
||||
***
|
||||
|
||||
## Running tests
|
||||
|
||||
While inside the repository
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
- [End2End Encryption](#end2end-encryption)
|
||||
- [Rate Limiting](#rate-limiting)
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
@@ -51,7 +51,7 @@ On the relay, the relay checks federation information set on the envelope and th
|
||||
When the relay receive a message that is destined to a `local` connected client, it queue it for delivery. The relay can maintain a queue of messages per twin to a limit. If the twin does not come back online to consume queued messages, the relay will start to drop messages for that specific twin client.
|
||||
|
||||
Once a twin come online and connect to its peer, the peer will receive all queued messages. the messages are pushed over the web-socket as they are received. the client then can decide how to handle them (a message can be a request or a response). A message type can be inspected as defined by the schema.
|
||||
***
|
||||
|
||||
# Overview of the Operation of RMB Relay
|
||||
|
||||

|
||||
@@ -201,7 +201,6 @@ A response message is defined as follows this is what is sent as a response by a
|
||||
|
||||
Your bot (server) need to make sure to set `destination` to the same value as the incoming request `source`
|
||||
|
||||
The
|
||||
> this response is what is pushed to `msgbus.system.reply`
|
||||
|
||||
```rust
|
||||
@@ -223,7 +222,7 @@ pub struct JsonOutgoingResponse {
|
||||
pub error: Option<JsonError>,
|
||||
}
|
||||
```
|
||||
***
|
||||
|
||||
# End2End Encryption
|
||||
|
||||
Relay is totally opaque to the messages. Our implementation of the relay does not poke into messages except for the routing attributes (source, and destinations addresses, and federation information). But since the relay is designed to be hosted by other 3rd parties (hence federation) you should
|
||||
@@ -246,7 +245,7 @@ As you already understand e2e is completely up to the peers to implement, and ev
|
||||
- derive the same shared key
|
||||
- `shared = ecdh(B.sk, A.pk)`
|
||||
- `plain-data = aes-gcm.decrypt(shared-key, nonce, encrypted)`
|
||||
***
|
||||
|
||||
# Rate Limiting
|
||||
|
||||
To avoid abuse of the server, and prevent DoS attacks on the relay, a rate limiter is used to limit the number of clients' requests.\
|
||||
|
||||
@@ -55,18 +55,16 @@ yarn add @threefold/grid_client
|
||||
To use the Grid Client locally, clone the repository then install the Grid Client:
|
||||
|
||||
- Clone the repository
|
||||
- ```bash
|
||||
git clone https://github.com/threefoldtech/tfgrid-sdk-ts
|
||||
```
|
||||
- Install the Grid Client
|
||||
- With yarn
|
||||
- ```bash
|
||||
yarn install
|
||||
```
|
||||
- With npm
|
||||
- ```bash
|
||||
npm install
|
||||
```
|
||||
```bash
|
||||
git clone https://github.com/threefoldtech/tfgrid-sdk-ts
|
||||
```
|
||||
- Install the Grid Client with yarn or npm
|
||||
```bash
|
||||
yarn install
|
||||
```
|
||||
```bash
|
||||
npm install
|
||||
```
|
||||
|
||||
> Note: In the directory **grid_client/scripts**, we provided a set of scripts to test the Grid Client.
|
||||
|
||||
@@ -94,11 +92,11 @@ Make sure to set the client configuration properly before using the Grid Client.
|
||||
The easiest way to test the installation is to run the following command with either yarn or npm to generate the Grid Client documentation:
|
||||
|
||||
* With yarn
|
||||
* ```
|
||||
```
|
||||
yarn run serve-docs
|
||||
```
|
||||
* With npm
|
||||
* ```
|
||||
```
|
||||
npm run serve-docs
|
||||
```
|
||||
|
||||
@@ -109,15 +107,13 @@ The easiest way to test the installation is to run the following command with ei
|
||||
You can explore the Grid Client by testing the different scripts proposed in **grid_client/scripts**.
|
||||
|
||||
- Update your customized deployments specs if needed
|
||||
- Run using [ts-node](https://www.npmjs.com/ts-node)
|
||||
- With yarn
|
||||
- ```bash
|
||||
yarn run ts-node --project tsconfig-node.json scripts/zdb.ts
|
||||
```
|
||||
- With npx
|
||||
- ```bash
|
||||
npx ts-node --project tsconfig-node.json scripts/zdb.ts
|
||||
```
|
||||
- Run using [ts-node](https://www.npmjs.com/ts-node) with yarn or npx
|
||||
```bash
|
||||
yarn run ts-node --project tsconfig-node.json scripts/zdb.ts
|
||||
```
|
||||
```bash
|
||||
npx ts-node --project tsconfig-node.json scripts/zdb.ts
|
||||
```
|
||||
|
||||
## Reference API
|
||||
|
||||
|
||||
@@ -60,33 +60,33 @@ To start the services for development or testing make sure first you have all th
|
||||
|
||||
- Clone this repo
|
||||
|
||||
```bash
|
||||
```
|
||||
git clone https://github.com/threefoldtech/tfgrid-sdk-go.git
|
||||
cd tfgrid-sdk-go/grid-proxy
|
||||
```
|
||||
|
||||
- The `Makefile` has all that you need to deal with Db, Explorer, Tests, and Docs.
|
||||
|
||||
```bash
|
||||
```
|
||||
make help # list all the available subcommands.
|
||||
```
|
||||
|
||||
- For a quick test explorer server.
|
||||
|
||||
```bash
|
||||
```
|
||||
make all-start e=<MNEMONICS>
|
||||
```
|
||||
|
||||
Now you can access the server at `http://localhost:8080`
|
||||
- Run the tests
|
||||
|
||||
```bash
|
||||
```
|
||||
make test-all
|
||||
```
|
||||
|
||||
- Generate docs.
|
||||
|
||||
```bash
|
||||
```
|
||||
make docs
|
||||
```
|
||||
|
||||
@@ -108,7 +108,7 @@ For more illustrations about the commands needed to work on the project, see the
|
||||
|
||||
- You can either build the project:
|
||||
|
||||
```bash
|
||||
```
|
||||
make build
|
||||
chmod +x cmd/proxy_server/server \
|
||||
&& mv cmd/proxy_server/server /usr/local/bin/gridproxy-server
|
||||
@@ -117,7 +117,7 @@ For more illustrations about the commands needed to work on the project, see the
|
||||
- Or download a release:
|
||||
Check the [releases](https://github.com/threefoldtech/tfgrid-sdk-go/releases) page and edit the next command with the chosen version.
|
||||
|
||||
```bash
|
||||
```
|
||||
wget https://github.com/threefoldtech/tfgrid-sdk-go/releases/download/v1.6.7-rc2/tfgridclient_proxy_1.6.7-rc2_linux_amd64.tar.gz \
|
||||
&& tar -xzf tfgridclient_proxy_1.6.7-rc2_linux_amd64.tar.gz \
|
||||
&& chmod +x server \
|
||||
@@ -128,7 +128,7 @@ For more illustrations about the commands needed to work on the project, see the
|
||||
|
||||
- Create the service file
|
||||
|
||||
```bash
|
||||
```
|
||||
cat << EOF > /etc/systemd/system/gridproxy-server.service
|
||||
[Unit]
|
||||
Description=grid proxy server
|
||||
|
||||
@@ -21,17 +21,17 @@ TFCMD is available as binaries. Make sure to download the latest release and to
|
||||
An easy way to use TFCMD is to download and extract the TFCMD binaries to your path.
|
||||
|
||||
- Download latest release from [releases](https://github.com/threefoldtech/tfgrid-sdk-go/releases)
|
||||
- ```
|
||||
wget <binaries_url>
|
||||
```
|
||||
```
|
||||
wget <binaries_url>
|
||||
```
|
||||
- Extract the binaries
|
||||
- ```
|
||||
tar -xvf <binaries_file>
|
||||
```
|
||||
```
|
||||
tar -xvf <binaries_file>
|
||||
```
|
||||
- Move `tfcmd` to any `$PATH` directory:
|
||||
```bash
|
||||
mv tfcmd /usr/local/bin
|
||||
```
|
||||
```
|
||||
mv tfcmd /usr/local/bin
|
||||
```
|
||||
|
||||
## Login
|
||||
|
||||
|
||||
@@ -23,14 +23,14 @@ To install TFROBOT, simply download and extract the TFROBOT binaries to your pat
|
||||
cd tfgrid-sdk-go
|
||||
```
|
||||
- Download latest release from [releases](https://github.com/threefoldtech/tfgrid-sdk-go/releases)
|
||||
- ```
|
||||
```
|
||||
wget https://github.com/threefoldtech/tfgrid-sdk-go/releases/download/v0.14.4/tfgrid-sdk-go_Linux_x86_64.tar.gz
|
||||
```
|
||||
- Extract the binaries
|
||||
- ```
|
||||
```
|
||||
tar -xvf tfgrid-sdk-go_Linux_x86_64.tar.gz
|
||||
```
|
||||
- Move `tfrobot` to any `$PATH` directory:
|
||||
```bash
|
||||
```
|
||||
mv tfrobot /usr/local/bin
|
||||
```
|
||||
@@ -743,18 +743,18 @@ To learn more about this process, [watch this great video](https://youtu.be/axvK
|
||||
If you've already done an SSH connection on your computer, the issue is most probably that the "host key has just been changed". To fix this, try one of those two solutions:
|
||||
|
||||
* Linux and MAC:
|
||||
* ```
|
||||
```
|
||||
sudo rm ~/.ssh/known_hosts
|
||||
```
|
||||
* Windows:
|
||||
* ```
|
||||
```
|
||||
rm ~/.ssh/known_hosts
|
||||
```
|
||||
|
||||
To be more specific, you can remove the probematic host:
|
||||
|
||||
* Windows, Linux and MAC:
|
||||
* ```
|
||||
```
|
||||
ssh-keygen -R <host>
|
||||
```
|
||||
|
||||
@@ -2074,7 +2074,7 @@ There can be many different fixes for this error. Here are some troubleshooting
|
||||
* [Flash the RAID controller](https://fohdeesha.com/docs/perc.html) (i.e. crossflashing), OR;
|
||||
* Change the controller to a Dell H310 controller (for Dell servers)
|
||||
* Try the command **badblocks** (replace **sda** with your specific disk). Note that this command will delete all the data on the disk
|
||||
* ```
|
||||
```
|
||||
sudo badblocks -svw -b 512 -t 0x00 /dev/sda
|
||||
```
|
||||
|
||||
@@ -2094,7 +2094,7 @@ Anyone experiencing frequently this issue where Z-OS sometimes detects an SSD as
|
||||
|
||||
* Boot a Ubuntu Linux live USB
|
||||
* Install **gnome-disks** if it isn't already installed:
|
||||
* ```
|
||||
```
|
||||
sudo apt install gnome-disks
|
||||
```
|
||||
* Open the application launcher and search for **Disks**
|
||||
@@ -2161,15 +2161,13 @@ Many different reasons can cause this issue. When you get that error, sometimes
|
||||
|
||||
* Fix 1:
|
||||
* Force the wiping of the disk:
|
||||
* ```
|
||||
```
|
||||
sudo wipefs -af /dev/sda
|
||||
```
|
||||
* Fix 2:
|
||||
* Unmount the disk then wipe it:
|
||||
* ```
|
||||
sudo umount /dev/sda
|
||||
```
|
||||
* ```
|
||||
sudo umount /dev/sda
|
||||
sudo wipefs -a /dev/sda
|
||||
```
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@
|
||||
- [Burn the Zero-OS Bootstrap Image](#burn-the-zero-os-bootstrap-image)
|
||||
- [CD/DVD BIOS](#cddvd-bios)
|
||||
- [USB Key BIOS+UEFI](#usb-key-biosuefi)
|
||||
- [BalenaEtcher (MAC, Linux, Windows)](#balenaetcher-mac-linux-windows)
|
||||
- [BalenaEtcher - MAC, Linux, Windows](#balenaetcher---mac-linux-windows)
|
||||
- [CLI (Linux)](#cli-linux)
|
||||
- [Rufus (Windows)](#rufus-windows)
|
||||
- [Additional Information (Optional)](#additional-information-optional)
|
||||
@@ -70,7 +70,7 @@ For the BIOS **ISO** image, download the file and burn it on a DVD.
|
||||
|
||||
There are many ways to burn the bootstrap image on a USB key. The easiest way that works for all operating systems is to use BalenaEtcher. We also provide other methods.
|
||||
|
||||
#### BalenaEtcher (MAC, Linux, Windows)
|
||||
#### BalenaEtcher - MAC, Linux, Windows
|
||||
|
||||
For **MAC**, **Linux** and **Windows**, you can use [BalenaEtcher](https://www.balena.io/etcher/) to load/flash the image on a USB stick. This program also formats the USB in the process. This will work for the option **EFI IMG** for UEFI boot, and with the option **USB** for BIOS boot. Simply follow the steps presented to you and make sure you select the bootstrap image file you downloaded previously.
|
||||
|
||||
|
||||
@@ -35,7 +35,7 @@ We cover the basic steps to install the GPU on your 3Node.
|
||||
* Install the GPU on the server
|
||||
* Note: You might need to move or remove some pieces of your server to make room for the GPU
|
||||
* (Optional) Boot the 3Node with a Linux distro (e.g. Ubuntu) and use the terminal to check if the GPU is recognized by the system
|
||||
* ```
|
||||
```
|
||||
sudo lshw -C Display
|
||||
```
|
||||
* Output example with an AMD Radeon (on the line `product: ...`)
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 9.0 KiB |
@@ -35,64 +35,4 @@ The ThreeFold Alpha minting tool will present the following information for each
|
||||
- SRU
|
||||
- HRU
|
||||
- TFT Farmed
|
||||
- Payout Address
|
||||
|
||||
<!-- NOTE: This is removed from the new dashboard, but might be brought back.
|
||||
|
||||
## Introduction
|
||||
|
||||
You can easily consult minting receipts of all your 3Nodes on the ThreeFold Dashboard to get essential minting information of your 3Nodes and your ThreeFold farm. With your minting receipt hash, you can then query the ThreeFold Alpha minting tool for further minting information.
|
||||
|
||||
## Download Minting Receipts of Your Farm
|
||||
|
||||
You can download minting receipts of your whole farm directly on the ThreeFold Dashboard.
|
||||
|
||||
- On the [ThreeFold Dashboard](https://dashboard.grid.tf/), go to **TFChain** -> **TF Minting Reports**
|
||||
- In the section **Your Farms**, on the left of your **Farm ID**, click on the down arrow button
|
||||
- Click on **Download Minting Receipts**
|
||||
|
||||
## Download Minting Receipts of a 3Node
|
||||
|
||||
You can download minting receipts of a single 3Node directly on the ThreeFold Dashboard.
|
||||
|
||||
- On the [ThreeFold Dashboard](https://dashboard.grid.tf/), go to **Portal** -> **Farms**
|
||||
- In the section **Your Farm Nodes**, on the left of your **Node ID**, click on the down arrow button
|
||||
- Click on **Node Statistics**
|
||||
- Click on **Download Node Receipt**
|
||||
|
||||
## Minting Receipts Information
|
||||
|
||||
The minting receipts contain the following information:
|
||||
|
||||
- Minting: <minting_receipt_hash>
|
||||
- start: <start of minting period>
|
||||
- end: <end of minting period>
|
||||
- TFT: <TFT minted by the 3Node>
|
||||
- Cloud Units: <3Node Resources>
|
||||
|
||||
## Alpha Minting Tool
|
||||
|
||||
You can query additional minting information by using the [Dashboard Alpha Minting tool](https://dashboard.grid.tf/other/minting).
|
||||
|
||||
- Download the minting receipts of your farm or of a single 3Node
|
||||
- Copy a minting receipt hash
|
||||
- Open the ThreeFold Alpha Minting tool by clicking on **Minting** on the left-side [ThreeFold Dashboard](https://dashboard.grid.tf/) menu
|
||||
- Paste the minting receipt hash
|
||||
|
||||
The ThreeFold Alpha minting tool will present the following information for each minting receipt hash:
|
||||
|
||||
- Node ID
|
||||
- Farm Name
|
||||
- Measured Uptime
|
||||
- Node Resources
|
||||
- CU
|
||||
- SU
|
||||
- NU
|
||||
- CRU
|
||||
- MRU
|
||||
- SRU
|
||||
- HRU
|
||||
- TFT Farmed
|
||||
- Payout Address
|
||||
|
||||
-->
|
||||
- Payout Address
|
||||
@@ -142,7 +142,7 @@ Once you've verified that the Farmerbot runs properly, you can stop the Farmerbo
|
||||
It is highly recommended to set a Ubuntu systemd service to keep the Farmerbot running after exiting the VM.
|
||||
|
||||
* Create the service file
|
||||
* ```
|
||||
```
|
||||
nano /etc/systemd/system/farmerbot.service
|
||||
```
|
||||
* Set the Farmerbot systemd service
|
||||
|
||||
@@ -30,7 +30,7 @@ We start by deploying a full VM on the ThreeFold Playground.
|
||||
* Minimum storage: 50GB
|
||||
* After deployment, note the VM IPv4 address
|
||||
* Connect to the VM via SSH
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_address
|
||||
```
|
||||
|
||||
@@ -39,39 +39,39 @@ We start by deploying a full VM on the ThreeFold Playground.
|
||||
We create a root-access user. Note that this step is optional.
|
||||
|
||||
* Once connected, create a new user with root access (for this guide we use "newuser")
|
||||
* ```
|
||||
```
|
||||
adduser newuser
|
||||
```
|
||||
* You should now see the new user directory
|
||||
* ```
|
||||
```
|
||||
ls /home
|
||||
```
|
||||
* Give sudo capacity to the new user
|
||||
* ```
|
||||
```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
* Switch to the new user
|
||||
* ```
|
||||
```
|
||||
su - newuser
|
||||
```
|
||||
* Create a directory to store the public key
|
||||
* ```
|
||||
```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
* Give read, write and execute permissions for the directory to the new user
|
||||
* ```
|
||||
```
|
||||
chmod 700 ~/.ssh
|
||||
```
|
||||
* Add the SSH public key in the file **authorized_keys** and save it
|
||||
* ```
|
||||
```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* Exit the VM
|
||||
* ```
|
||||
```
|
||||
exit
|
||||
```
|
||||
* Reconnect with the new user
|
||||
* ```
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
|
||||
@@ -81,19 +81,19 @@ We set a firewall to monitor and control incoming and outgoing network traffic.
|
||||
For our security rules, we want to allow SSH, HTTP and HTTPS (443 and 8443).
|
||||
We thus add the following rules:
|
||||
* Allow SSH (port 22)
|
||||
* ```
|
||||
```
|
||||
sudo ufw allow ssh
|
||||
```
|
||||
* Allow port 4001
|
||||
* ```
|
||||
```
|
||||
sudo ufw allow 4001
|
||||
```
|
||||
* To enable the firewall, write the following:
|
||||
* ```
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
* To see the current security rules, write the following:
|
||||
* ```
|
||||
```
|
||||
sudo ufw status verbose
|
||||
```
|
||||
You now have enabled the firewall with proper security rules for your IPFS deployment.
|
||||
@@ -109,23 +109,23 @@ If you want to run pubsub capabilities, you need to allow **port 8081**. For mor
|
||||
|
||||
We install the [IPFS Kubo binary](https://docs.ipfs.tech/install/command-line/#install-official-binary-distributions).
|
||||
* Download the binary
|
||||
* ```
|
||||
```
|
||||
wget https://dist.ipfs.tech/kubo/v0.24.0/kubo_v0.24.0_linux-amd64.tar.gz
|
||||
```
|
||||
* Unzip the file
|
||||
* ```
|
||||
```
|
||||
tar -xvzf kubo_v0.24.0_linux-amd64.tar.gz
|
||||
```
|
||||
* Change directory
|
||||
* ```
|
||||
```
|
||||
cd kubo
|
||||
```
|
||||
* Run the install script
|
||||
* ```
|
||||
```
|
||||
sudo bash install.sh
|
||||
```
|
||||
* Verify that IPFS Kubo is properly installed
|
||||
* ```
|
||||
```
|
||||
ipfs --version
|
||||
```
|
||||
|
||||
@@ -134,23 +134,23 @@ We install the [IPFS Kubo binary](https://docs.ipfs.tech/install/command-line/#i
|
||||
We initialize IPFS and run the IPFS daemon.
|
||||
|
||||
* Initialize IPFS
|
||||
* ```
|
||||
```
|
||||
ipfs init --profile server
|
||||
```
|
||||
* Increase the storage capacity (optional)
|
||||
* ```
|
||||
```
|
||||
ipfs config Datastore.StorageMax 30GB
|
||||
```
|
||||
* Run the IPFS daemon
|
||||
* ```
|
||||
```
|
||||
ipfs daemon
|
||||
```
|
||||
* Set an Ubuntu systemd service to keep the IPFS daemon running after exiting the VM
|
||||
* ```
|
||||
```
|
||||
sudo nano /etc/systemd/system/ipfs.service
|
||||
```
|
||||
* Enter the systemd info
|
||||
* ```
|
||||
```
|
||||
[Unit]
|
||||
Description=IPFS Daemon
|
||||
[Service]
|
||||
@@ -163,27 +163,27 @@ We initialize IPFS and run the IPFS daemon.
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
* Enable the service
|
||||
* ```
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable ipfs
|
||||
sudo systemctl start ipfs
|
||||
```
|
||||
* Verify that the IPFS daemon is properly running
|
||||
* ```
|
||||
```
|
||||
sudo systemctl status ipfs
|
||||
```
|
||||
## Final Verification
|
||||
We reboot and reconnect to the VM and verify that IPFS is properly running as a final verification.
|
||||
* Reboot the VM
|
||||
* ```
|
||||
```
|
||||
sudo reboot
|
||||
```
|
||||
* Reconnect to the VM
|
||||
* ```
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
* Check that the IPFS daemon is running
|
||||
* ```
|
||||
```
|
||||
ipfs swarm peers
|
||||
```
|
||||
## Questions and Feedback
|
||||
|
||||
@@ -31,7 +31,7 @@ We start by deploying a micro VM on the ThreeFold Playground.
|
||||
* Minimum storage: 50GB
|
||||
* After deployment, note the VM IPv4 address
|
||||
* Connect to the VM via SSH
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_address
|
||||
```
|
||||
|
||||
@@ -40,11 +40,11 @@ We start by deploying a micro VM on the ThreeFold Playground.
|
||||
We install the prerequisites before installing and setting IPFS.
|
||||
|
||||
* Update Ubuntu
|
||||
* ```
|
||||
```
|
||||
apt update
|
||||
```
|
||||
* Install nano and ufw
|
||||
* ```
|
||||
```
|
||||
apt install nano && apt install ufw -y
|
||||
```
|
||||
|
||||
@@ -57,20 +57,20 @@ For our security rules, we want to allow SSH, HTTP and HTTPS (443 and 8443).
|
||||
We thus add the following rules:
|
||||
|
||||
* Allow SSH (port 22)
|
||||
* ```
|
||||
```
|
||||
ufw allow ssh
|
||||
```
|
||||
* Allow port 4001
|
||||
* ```
|
||||
```
|
||||
ufw allow 4001
|
||||
```
|
||||
* To enable the firewall, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
* To see the current security rules, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw status verbose
|
||||
```
|
||||
|
||||
@@ -91,23 +91,23 @@ If you want to run pubsub capabilities, you need to allow **port 8081**. For mor
|
||||
We install the [IPFS Kubo binary](https://docs.ipfs.tech/install/command-line/#install-official-binary-distributions).
|
||||
|
||||
* Download the binary
|
||||
* ```
|
||||
```
|
||||
wget https://dist.ipfs.tech/kubo/v0.24.0/kubo_v0.24.0_linux-amd64.tar.gz
|
||||
```
|
||||
* Unzip the file
|
||||
* ```
|
||||
```
|
||||
tar -xvzf kubo_v0.24.0_linux-amd64.tar.gz
|
||||
```
|
||||
* Change directory
|
||||
* ```
|
||||
```
|
||||
cd kubo
|
||||
```
|
||||
* Run the install script
|
||||
* ```
|
||||
```
|
||||
bash install.sh
|
||||
```
|
||||
* Verify that IPFS Kubo is properly installed
|
||||
* ```
|
||||
```
|
||||
ipfs --version
|
||||
```
|
||||
|
||||
@@ -116,15 +116,15 @@ We install the [IPFS Kubo binary](https://docs.ipfs.tech/install/command-line/#i
|
||||
We initialize IPFS and run the IPFS daemon.
|
||||
|
||||
* Initialize IPFS
|
||||
* ```
|
||||
```
|
||||
ipfs init --profile server
|
||||
```
|
||||
* Increase the storage capacity (optional)
|
||||
* ```
|
||||
```
|
||||
ipfs config Datastore.StorageMax 30GB
|
||||
```
|
||||
* Run the IPFS daemon
|
||||
* ```
|
||||
```
|
||||
ipfs daemon
|
||||
```
|
||||
|
||||
@@ -133,19 +133,19 @@ We initialize IPFS and run the IPFS daemon.
|
||||
We set the IPFS daemon with zinit. This will make sure that the IPFS daemon starts at each VM reboot or if it stops functioning momentarily.
|
||||
|
||||
* Create the yaml file
|
||||
* ```
|
||||
```
|
||||
nano /etc/zinit/ipfs.yaml
|
||||
```
|
||||
* Set the execution command
|
||||
* ```
|
||||
```
|
||||
exec: /usr/local/bin/ipfs daemon
|
||||
```
|
||||
* Run the IPFS daemon with the zinit monitor command
|
||||
* ```
|
||||
```
|
||||
zinit monitor ipfs
|
||||
```
|
||||
* Verify that the IPFS daemon is running
|
||||
* ```
|
||||
```
|
||||
ipfs swarm peers
|
||||
```
|
||||
|
||||
@@ -154,11 +154,11 @@ We set the IPFS daemon with zinit. This will make sure that the IPFS daemon star
|
||||
We reboot and reconnect to the VM and verify that IPFS is properly running as a final verification.
|
||||
|
||||
* Reboot the VM
|
||||
* ```
|
||||
```
|
||||
reboot -f
|
||||
```
|
||||
* Reconnect to the VM and verify that the IPFS daemon is running
|
||||
* ```
|
||||
```
|
||||
ipfs swarm peers
|
||||
```
|
||||
|
||||
|
||||
@@ -24,6 +24,7 @@
|
||||
- [Become the superuser (su) on Linux](#become-the-superuser-su-on-linux)
|
||||
- [Exit a session](#exit-a-session)
|
||||
- [Know the current user](#know-the-current-user)
|
||||
- [See the path of a package](#see-the-path-of-a-package)
|
||||
- [Set the path of a package](#set-the-path-of-a-package)
|
||||
- [See the current path](#see-the-current-path-1)
|
||||
- [Find the current shell](#find-the-current-shell)
|
||||
@@ -127,11 +128,11 @@ You can also set a number of counts with `-c` on Linux and MAC and `-n` on Windo
|
||||
Here are the steps to install [Go](https://go.dev/).
|
||||
|
||||
* Install go
|
||||
* ```
|
||||
```
|
||||
sudo apt install golang-go
|
||||
```
|
||||
* Verify that go is properly installed
|
||||
* ```
|
||||
```
|
||||
go version
|
||||
```
|
||||
|
||||
@@ -142,19 +143,19 @@ Here are the steps to install [Go](https://go.dev/).
|
||||
Follow those steps to install [Brew](https://brew.sh/)
|
||||
|
||||
* Installation command from Brew:
|
||||
* ```
|
||||
```
|
||||
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
|
||||
```
|
||||
* Add the path to the **.profile** directory. Replace <user_name> by your username.
|
||||
* ```
|
||||
```
|
||||
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/<user_name>/.profile
|
||||
```
|
||||
* Evaluation the following:
|
||||
* ```
|
||||
```
|
||||
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
|
||||
```
|
||||
* Verify the installation
|
||||
* ```
|
||||
```
|
||||
brew doctor
|
||||
```
|
||||
|
||||
@@ -163,27 +164,27 @@ Follow those steps to install [Brew](https://brew.sh/)
|
||||
### Brew basic commands
|
||||
|
||||
* To update brew in general:
|
||||
* ```
|
||||
```
|
||||
brew update
|
||||
```
|
||||
* To update a specific package:
|
||||
* ```
|
||||
```
|
||||
brew update <package_name>
|
||||
```
|
||||
* To install a package:
|
||||
* ```
|
||||
```
|
||||
brew install <package_name>
|
||||
```
|
||||
* To uninstall a package:
|
||||
* ```
|
||||
```
|
||||
brew uninstall <package_name>
|
||||
```
|
||||
* To search a package:
|
||||
* ```
|
||||
```
|
||||
brew search <package_name>
|
||||
```
|
||||
* [Uninstall Brew](https://github.com/homebrew/install#uninstall-homebrew)
|
||||
* ```
|
||||
```
|
||||
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/uninstall.sh)"
|
||||
```
|
||||
|
||||
@@ -194,11 +195,11 @@ Follow those steps to install [Brew](https://brew.sh/)
|
||||
Installing Terraform with Brew is very simple by following the [Terraform documentation](https://developer.hashicorp.com/terraform/downloads).
|
||||
|
||||
* Compile HashiCorp software on Homebrew's infrastructure
|
||||
* ```
|
||||
```
|
||||
brew tap hashicorp/tap
|
||||
```
|
||||
* Install Terraform
|
||||
* ```
|
||||
```
|
||||
brew install hashicorp/tap/terraform
|
||||
```
|
||||
|
||||
@@ -207,27 +208,27 @@ Installing Terraform with Brew is very simple by following the [Terraform docume
|
||||
### Yarn basic commands
|
||||
|
||||
* Add a package
|
||||
* ```
|
||||
```
|
||||
yarn add
|
||||
```
|
||||
* Initialize the development of a package
|
||||
* ```
|
||||
```
|
||||
yarn init
|
||||
```
|
||||
* Install all the dependencies in the **package.json** file
|
||||
* ```
|
||||
```
|
||||
yarn install
|
||||
```
|
||||
* Publish a package to a package manager
|
||||
* ```
|
||||
```
|
||||
yarn publish
|
||||
```
|
||||
* Remove unused package from the current package
|
||||
* ```
|
||||
```
|
||||
yarn remove
|
||||
```
|
||||
* Clean the cache
|
||||
* ```
|
||||
```
|
||||
yarn cache clean
|
||||
```
|
||||
|
||||
@@ -260,11 +261,11 @@ ls -ld .?*
|
||||
You can use **tree** to display the files and organization of a directory:
|
||||
|
||||
* General command
|
||||
* ```
|
||||
```
|
||||
tree
|
||||
```
|
||||
* View hidden files
|
||||
* ```
|
||||
```
|
||||
tree -a
|
||||
```
|
||||
|
||||
@@ -336,10 +337,10 @@ which <application_name>
|
||||
|
||||
On MAC and Linux, you can use **coreutils** and **realpath** from Brew:
|
||||
|
||||
* ```
|
||||
```
|
||||
brew install coreutils
|
||||
```
|
||||
* ```
|
||||
```
|
||||
realpath file_name
|
||||
```
|
||||
|
||||
@@ -350,11 +351,11 @@ On MAC and Linux, you can use **coreutils** and **realpath** from Brew:
|
||||
You can use either command:
|
||||
|
||||
* Option 1
|
||||
* ```
|
||||
```
|
||||
sudo -i
|
||||
```
|
||||
* Option 2
|
||||
* ```
|
||||
```
|
||||
sudo -s
|
||||
```
|
||||
|
||||
@@ -364,10 +365,10 @@ You can use either command:
|
||||
|
||||
You can use either command depending on your shell:
|
||||
|
||||
* ```
|
||||
```
|
||||
exit
|
||||
```
|
||||
* ```
|
||||
```
|
||||
logout
|
||||
```
|
||||
|
||||
@@ -377,7 +378,7 @@ You can use either command depending on your shell:
|
||||
|
||||
You can use the following command:
|
||||
|
||||
* ```
|
||||
```
|
||||
whoami
|
||||
```
|
||||
|
||||
@@ -387,7 +388,7 @@ You can use the following command:
|
||||
|
||||
To see the path of a package, you can use the following command:
|
||||
|
||||
* ```
|
||||
```
|
||||
whereis <package_name>
|
||||
```
|
||||
|
||||
@@ -414,11 +415,11 @@ pwd
|
||||
### Find the current shell
|
||||
|
||||
* Compact version
|
||||
* ```
|
||||
```
|
||||
echo $SHELL
|
||||
```
|
||||
* Detailed version
|
||||
* ```
|
||||
```
|
||||
ls -l /proc/$$/exe
|
||||
```
|
||||
|
||||
@@ -427,35 +428,35 @@ pwd
|
||||
### SSH into Remote Server
|
||||
|
||||
* Create SSH key pair
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Install openssh-client on the local computer*
|
||||
* ```
|
||||
```
|
||||
sudo apt install openssh-client
|
||||
```
|
||||
* Install openssh-server on the remote computer*
|
||||
* ```
|
||||
```
|
||||
sudo apt install openssh-server
|
||||
```
|
||||
* Copy public key
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Create the ssh directory on the remote computer
|
||||
* ```
|
||||
```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
* Add public key in the file **authorized_keys** on the remote computer
|
||||
* ```
|
||||
```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* Check openssh-server status
|
||||
* ```
|
||||
```
|
||||
sudo service ssh status
|
||||
```
|
||||
* SSH into the remote machine
|
||||
* ```
|
||||
```
|
||||
ssh <username>@<remote_server_IP_or_hostname>
|
||||
```
|
||||
|
||||
@@ -468,11 +469,11 @@ To enable remote login on a MAC, [read this section](#enable-remote-login-on-mac
|
||||
### Replace a string by another string in a text file
|
||||
|
||||
* Replace one string by another (e.g. **old_string**, **new_string**)
|
||||
* ```
|
||||
```
|
||||
sed -i 's/old_string/new_string/g' <file_path>/<file_name>
|
||||
```
|
||||
* Use environment variables (double quotes)
|
||||
* ```
|
||||
```
|
||||
sed -i "s/old_string/$env_variable/g" <file_path>/<file_name>
|
||||
```
|
||||
|
||||
@@ -529,11 +530,11 @@ date
|
||||
You can use [Dig](https://man.archlinux.org/man/dig.1) to gather DNS information of a website
|
||||
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
dig <website.tld>
|
||||
```
|
||||
* Example
|
||||
* ```
|
||||
```
|
||||
dig threefold.io
|
||||
```
|
||||
|
||||
@@ -546,31 +547,31 @@ You can also use online tools such as [DNS Checker](https://dnschecker.org/).
|
||||
We present one of many ways to partition and mount a disk.
|
||||
|
||||
* Create partition with [gparted](https://gparted.org/)
|
||||
* ```
|
||||
```
|
||||
sudo gparted
|
||||
```
|
||||
* Find the disk you want to mount (e.g. **sdb**)
|
||||
* ```
|
||||
```
|
||||
sudo fdisk -l
|
||||
```
|
||||
* Create a directory to mount the disk to
|
||||
* ```
|
||||
```
|
||||
sudo mkdir /mnt/disk
|
||||
```
|
||||
* Open fstab
|
||||
* ```
|
||||
```
|
||||
sudo nano /etc/fstab
|
||||
```
|
||||
* Append the following to the fstab with the proper disk path (e.g. **/dev/sdb**) and mount point (e.g. **/mnt/disk**)
|
||||
* ```
|
||||
```
|
||||
/dev/sdb /mnt/disk ext4 defaults 0 0
|
||||
```
|
||||
* Mount the disk
|
||||
* ```
|
||||
```
|
||||
sudo mount /mnt/disk
|
||||
```
|
||||
* Add permissions (as needed)
|
||||
* ```
|
||||
```
|
||||
sudo chmod -R 0777 /mnt/disk
|
||||
```
|
||||
|
||||
@@ -583,36 +584,36 @@ We present one of many ways to partition and mount a disk.
|
||||
You can use [gocryptfs](https://github.com/rfjakob/gocryptfs) to encrypt files.
|
||||
|
||||
* Install gocryptfs
|
||||
* ```
|
||||
```
|
||||
apt install gocryptfs
|
||||
```
|
||||
* Create a vault directory (e.g. **vaultdir**) and a mount directory (e.g. **mountdir**)
|
||||
* ```
|
||||
```
|
||||
mkdir vaultdir mountdir
|
||||
```
|
||||
* Initiate the vault
|
||||
* ```
|
||||
```
|
||||
gocryptfs -init vaultdir
|
||||
```
|
||||
* Mount the mount directory with the vault
|
||||
* ```
|
||||
```
|
||||
gocryptfs vaultdir mountdir
|
||||
```
|
||||
* You can now create files in the folder. For example:
|
||||
* ```
|
||||
```
|
||||
touch mountdir/test.txt
|
||||
```
|
||||
* The new file **test.txt** is now encrypted in the vault
|
||||
* ```
|
||||
```
|
||||
ls vaultdir
|
||||
```
|
||||
* To unmount the mountedvault folder:
|
||||
* Option 1
|
||||
* ```
|
||||
```
|
||||
fusermount -u mountdir
|
||||
```
|
||||
* Option 2
|
||||
* ```
|
||||
```
|
||||
rmdir mountdir
|
||||
```
|
||||
|
||||
@@ -623,27 +624,27 @@ To encrypt files, you can use [Veracrypt](https://www.veracrypt.fr/en/Home.html)
|
||||
|
||||
* Veracrypt GUI
|
||||
* Download the package
|
||||
* ```
|
||||
```
|
||||
wget https://launchpad.net/veracrypt/trunk/1.25.9/+download/veracrypt-1.25.9-Ubuntu-22.04-amd64.deb
|
||||
```
|
||||
* Install the package
|
||||
* ```
|
||||
```
|
||||
dpkg -i ./veracrypt-1.25.9-Ubuntu-22.04-amd64.deb
|
||||
```
|
||||
* Veracrypt console only
|
||||
* Download the package
|
||||
* ```
|
||||
```
|
||||
wget https://launchpad.net/veracrypt/trunk/1.25.9/+download/veracrypt-console-1.25.9-Ubuntu-22.04-amd64.deb
|
||||
```
|
||||
* Install the package
|
||||
* ```
|
||||
```
|
||||
dpkg -i ./veracrypt-console-1.25.9-Ubuntu-22.04-amd64.deb
|
||||
```
|
||||
|
||||
You can visit [Veracrypt download page](https://www.veracrypt.fr/en/Downloads.html) to get the newest releases.
|
||||
|
||||
* To run Veracrypt
|
||||
* ```
|
||||
```
|
||||
veracrypt
|
||||
```
|
||||
* Veracrypt documentation is very complete. To begin using the application, visit the [Beginner's Tutorial](https://www.veracrypt.fr/en/Beginner%27s%20Tutorial.html).
|
||||
@@ -661,11 +662,11 @@ ifconfig
|
||||
### See identity and info of IP address
|
||||
|
||||
* See abuses related to an IP address:
|
||||
* ```
|
||||
```
|
||||
https://www.abuseipdb.com/check/<IP_Address>
|
||||
```
|
||||
* See general information of an IP address:
|
||||
* ```
|
||||
```
|
||||
https://www.whois.com/whois/<IP_Address>
|
||||
```
|
||||
|
||||
@@ -674,124 +675,124 @@ ifconfig
|
||||
### ip basic commands
|
||||
|
||||
* Manage and display the state of all network
|
||||
* ```
|
||||
```
|
||||
ip link
|
||||
```
|
||||
* Display IP Addresses and property information (abbreviation of address)
|
||||
* ```
|
||||
```
|
||||
ip addr
|
||||
```
|
||||
* Display and alter the routing table
|
||||
* ```
|
||||
```
|
||||
ip route
|
||||
```
|
||||
* Manage and display multicast IP addresses
|
||||
* ```
|
||||
```
|
||||
ip maddr
|
||||
```
|
||||
* Show neighbour object
|
||||
* ```
|
||||
```
|
||||
ip neigh
|
||||
```
|
||||
* Display a list of commands and arguments for
|
||||
each subcommand
|
||||
* ```
|
||||
```
|
||||
ip help
|
||||
```
|
||||
* Add an address
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip addr add
|
||||
```
|
||||
* Example: set IP address to device **enp0**
|
||||
* ```
|
||||
```
|
||||
ip addr add 192.168.3.4/24 dev enp0
|
||||
```
|
||||
* Delete an address
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip addr del
|
||||
```
|
||||
* Example: set IP address to device **enp0**
|
||||
* ```
|
||||
```
|
||||
ip addr del 192.168.3.4/24 dev enp0
|
||||
```
|
||||
* Alter the status of an interface
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip link set
|
||||
```
|
||||
* Example 1: Bring interface online (here device **em2**)
|
||||
* ```
|
||||
```
|
||||
ip link set em2 up
|
||||
```
|
||||
* Example 2: Bring interface offline (here device **em2**)
|
||||
* ```
|
||||
```
|
||||
ip link set em2 down
|
||||
```
|
||||
* Add a multicast address
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip maddr add
|
||||
```
|
||||
* Example : set IP address to device **em2**
|
||||
* ```
|
||||
```
|
||||
ip maddr add 33:32:00:00:00:01 dev em2
|
||||
```
|
||||
* Delete a multicast address
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip maddr del
|
||||
```
|
||||
* Example: set IP address to device **em2**
|
||||
* ```
|
||||
```
|
||||
ip maddr del 33:32:00:00:00:01 dev em2
|
||||
```
|
||||
* Add a routing table entry
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip route add
|
||||
```
|
||||
* Example 1: Add a default route (for all addresses) via a local gateway
|
||||
* ```
|
||||
```
|
||||
ip route add default via 192.168.1.1 dev em1
|
||||
```
|
||||
* Example 2: Add a route to 192.168.3.0/24 via the gateway at 192.168.3.2
|
||||
* ```
|
||||
```
|
||||
ip route add 192.168.3.0/24 via 192.168.3.2
|
||||
```
|
||||
* Example 3: Add a route to 192.168.1.0/24 that can be reached on
|
||||
device em1
|
||||
* ```
|
||||
```
|
||||
ip route add 192.168.1.0/24 dev em1
|
||||
```
|
||||
* Delete a routing table entry
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip route delete
|
||||
```
|
||||
* Example: Delete the route for 192.168.1.0/24 via the gateway at
|
||||
192.168.1.1
|
||||
* ```
|
||||
```
|
||||
ip route delete 192.168.1.0/24 via 192.168.1.1
|
||||
```
|
||||
* Replace, or add, a route
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip route replace
|
||||
```
|
||||
* Example: Replace the defined route for 192.168.1.0/24 to use
|
||||
device em1
|
||||
* ```
|
||||
```
|
||||
ip route replace 192.168.1.0/24 dev em1
|
||||
```
|
||||
* Display the route an address will take
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
ip route get
|
||||
```
|
||||
* Example: Display the route taken for IP 192.168.18.25
|
||||
* ```
|
||||
```
|
||||
ip route replace 192.168.18.25/24 dev enp0
|
||||
```
|
||||
|
||||
@@ -804,23 +805,23 @@ References: https://www.commandlinux.com/man-page/man8/ip.8.html
|
||||
### Display socket statistics
|
||||
|
||||
* Show all sockets
|
||||
* ```
|
||||
```
|
||||
ss -a
|
||||
```
|
||||
* Show detailed socket information
|
||||
* ```
|
||||
```
|
||||
ss -e
|
||||
```
|
||||
* Show timer information
|
||||
* ```
|
||||
```
|
||||
ss -o
|
||||
```
|
||||
* Do not resolve address
|
||||
* ```
|
||||
```
|
||||
ss -n
|
||||
```
|
||||
* Show process using the socket
|
||||
* ```
|
||||
```
|
||||
ss -p
|
||||
```
|
||||
|
||||
@@ -833,19 +834,19 @@ References: https://www.commandlinux.com/man-page/man8/ss.8.html
|
||||
### Query or control network driver and hardware settings
|
||||
|
||||
* Display ring buffer for a device (e.g. **eth0**)
|
||||
* ```
|
||||
```
|
||||
ethtool -g eth0
|
||||
```
|
||||
* Display driver information for a device (e.g. **eth0**)
|
||||
* ```
|
||||
```
|
||||
ethtool -i eth0
|
||||
```
|
||||
* Identify eth0 by sight, e.g. by causing LEDs to blink on the network port
|
||||
* ```
|
||||
```
|
||||
ethtool -p eth0
|
||||
```
|
||||
* Display network and driver statistics for a device (e.g. **eth0**)
|
||||
* ```
|
||||
```
|
||||
ethtool -S eth0
|
||||
```
|
||||
|
||||
@@ -866,21 +867,21 @@ cat /sys/class/net/<ethernet_device>/carrier
|
||||
### Add IP address to hardware port (ethernet)
|
||||
|
||||
* Find ethernet port ID on both computers
|
||||
* ```
|
||||
```
|
||||
ip a
|
||||
```
|
||||
* Add IP address (DHCO or static)
|
||||
* Computer 1
|
||||
* ```
|
||||
```
|
||||
ip addr add <Private_IP_Address_1>/24 dev <ethernet_interface_1>
|
||||
```
|
||||
* Computer 2
|
||||
* ```
|
||||
```
|
||||
ip addr add <Private_IP_Address_2>/24 dev <ethernet_interface_2>
|
||||
```
|
||||
|
||||
* [Ping](#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the address to confirm connection
|
||||
* ```
|
||||
```
|
||||
ping <Private_IP_Address>
|
||||
```
|
||||
|
||||
@@ -918,11 +919,11 @@ You can use the following template when you set an IP address manually:
|
||||
You can use the following template to add arguments when running a script:
|
||||
|
||||
* Option 1
|
||||
* ```
|
||||
```
|
||||
./example_script.sh arg1 arg2
|
||||
```
|
||||
* Option 2
|
||||
* ```
|
||||
```
|
||||
sh example_script.sh "arg1" "arg2"
|
||||
```
|
||||
|
||||
@@ -930,16 +931,16 @@ You can use the following template to add arguments when running a script:
|
||||
|
||||
* Write a script
|
||||
* File: `example_script.sh`
|
||||
* ```bash
|
||||
```bash
|
||||
#!/bin/sh
|
||||
echo $@
|
||||
```
|
||||
* Give permissions
|
||||
* ```bash
|
||||
```bash
|
||||
chmod +x ./example_script.sh
|
||||
```
|
||||
* Run the script with arguments
|
||||
* ```bash
|
||||
```bash
|
||||
sh example_script.sh arg1 arg2
|
||||
```
|
||||
|
||||
@@ -947,7 +948,7 @@ You can use the following template to add arguments when running a script:
|
||||
### Iterate over arguments
|
||||
|
||||
* Write the script
|
||||
* ```bash
|
||||
```bash
|
||||
# iterate_script.sh
|
||||
#!/bin/bash
|
||||
for i; do
|
||||
@@ -955,16 +956,16 @@ You can use the following template to add arguments when running a script:
|
||||
done
|
||||
```
|
||||
* Give permissions
|
||||
* ```
|
||||
```
|
||||
chmod +x ./iterate_script.sh
|
||||
```
|
||||
* Run the script with arguments
|
||||
* ```
|
||||
```
|
||||
sh iterate_script.sh arg1 arg2
|
||||
```
|
||||
|
||||
* The following script is equivalent
|
||||
* ```bash
|
||||
```bash
|
||||
# iterate_script.sh
|
||||
#/bin/bash
|
||||
for i in $*; do
|
||||
@@ -977,7 +978,7 @@ You can use the following template to add arguments when running a script:
|
||||
### Count lines in files given as arguments
|
||||
|
||||
* Write the script
|
||||
* ```bash
|
||||
```bash
|
||||
# count_lines.sh
|
||||
#!/bin/bash
|
||||
for i in $*; do
|
||||
@@ -986,11 +987,11 @@ You can use the following template to add arguments when running a script:
|
||||
done
|
||||
```
|
||||
* Give permissions
|
||||
* ```
|
||||
```
|
||||
chmod +x ./count_lines.sh
|
||||
```
|
||||
* Run the script with arguments (files). Here we use the script itself as an example.
|
||||
* ```
|
||||
```
|
||||
sh count_lines.sh count_lines.sh
|
||||
```
|
||||
|
||||
@@ -999,14 +1000,14 @@ You can use the following template to add arguments when running a script:
|
||||
### Find path of a file
|
||||
|
||||
* Write the script
|
||||
* ```bash
|
||||
```bash
|
||||
# find.sh
|
||||
#!/bin/bash
|
||||
|
||||
find / -iname $1 2> /dev/null
|
||||
```
|
||||
* Run the script
|
||||
* ```
|
||||
```
|
||||
sh find.sh <filename>
|
||||
```
|
||||
|
||||
@@ -1015,13 +1016,13 @@ You can use the following template to add arguments when running a script:
|
||||
### Print how many arguments are passed in a script
|
||||
|
||||
* Write the script
|
||||
* ```bash
|
||||
```bash
|
||||
# print_qty_args.sh
|
||||
#!/bin/bash
|
||||
echo This script was passed $# arguments
|
||||
```
|
||||
* Run the script
|
||||
* ```
|
||||
```
|
||||
sh print_qty_args.sh <filename>
|
||||
```
|
||||
|
||||
@@ -1050,7 +1051,7 @@ Note that the Terraform documentation also covers other methods to install Terra
|
||||
|
||||
* Option 1:
|
||||
* Use the following command line:
|
||||
* ```
|
||||
```
|
||||
systemsetup -setremotelogin on
|
||||
```
|
||||
* Option 2
|
||||
@@ -1063,7 +1064,7 @@ Note that the Terraform documentation also covers other methods to install Terra
|
||||
|
||||
* Open **Finder** \> **Go** \> **Go to Folder**
|
||||
* Paste this path
|
||||
* ```
|
||||
```
|
||||
~/Library/Caches
|
||||
```
|
||||
|
||||
@@ -1087,15 +1088,15 @@ To install Chocolatey on Windows, we follow the [official Chocolatey website](ht
|
||||
|
||||
* Run PowerShell as Administrator
|
||||
* Check if **Get-ExecutionPolicy** is restricted
|
||||
* ```
|
||||
```
|
||||
Get-ExecutionPolicy
|
||||
```
|
||||
* If it is restricted, run the following command:
|
||||
* ```
|
||||
```
|
||||
Set-ExecutionPolicy AllSigned
|
||||
```
|
||||
* Install Chocolatey
|
||||
* ```
|
||||
```
|
||||
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
|
||||
```
|
||||
* Note: You might need to restart PowerShell to use Chocolatey
|
||||
@@ -1107,7 +1108,7 @@ To install Chocolatey on Windows, we follow the [official Chocolatey website](ht
|
||||
Once you've installed Chocolatey on Windows, installing Terraform is as simple as can be:
|
||||
|
||||
* Install Terraform with Chocolatey
|
||||
* ```
|
||||
```
|
||||
choco install terraform
|
||||
```
|
||||
|
||||
|
||||
@@ -70,16 +70,16 @@ sudo sh get-docker.sh
|
||||
To completely remove docker from your machine, you can follow these steps:
|
||||
|
||||
* List the docker packages
|
||||
* ```
|
||||
```
|
||||
dpkg -l | grep -i docker
|
||||
```
|
||||
* Purge and autoremove docker
|
||||
* ```
|
||||
```
|
||||
apt-get purge -y docker-engine docker docker.io docker-ce docker-ce-cli docker-compose-plugin
|
||||
apt-get autoremove -y --purge docker-engine docker docker.io docker-ce docker-compose-plugin
|
||||
```
|
||||
* Remove the docker files and folders
|
||||
* ```
|
||||
```
|
||||
rm -rf /var/lib/docker /etc/docker
|
||||
rm /etc/apparmor.d/docker
|
||||
groupdel docker
|
||||
@@ -93,11 +93,11 @@ You can also use the command **whereis docker** to see if any Docker folders and
|
||||
### List containers
|
||||
|
||||
* List only running containers
|
||||
* ```
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
* List all containers (running + stopped)
|
||||
* ```
|
||||
```
|
||||
docker ps -a
|
||||
```
|
||||
|
||||
@@ -108,15 +108,15 @@ You can also use the command **whereis docker** to see if any Docker folders and
|
||||
To pull an image from [Docker Hub](https://hub.docker.com/):
|
||||
|
||||
* Pull an image
|
||||
* ```
|
||||
```
|
||||
docker pull <image_name>
|
||||
```
|
||||
* Pull an image with the tag
|
||||
* ```
|
||||
```
|
||||
docker pull <image_name>:tag
|
||||
```
|
||||
* Pull all tags of an image
|
||||
* ```
|
||||
```
|
||||
docker pull <image_name> -a
|
||||
```
|
||||
|
||||
@@ -127,15 +127,15 @@ To pull an image from [Docker Hub](https://hub.docker.com/):
|
||||
To pull an image to [Docker Hub](https://hub.docker.com/):
|
||||
|
||||
* Push an image
|
||||
* ```
|
||||
```
|
||||
docker push <image_name>
|
||||
```
|
||||
* Push an image with the tag
|
||||
* ```
|
||||
```
|
||||
docker push <image_name>:tag
|
||||
```
|
||||
* Push all tags of an image
|
||||
* ```
|
||||
```
|
||||
docker pull <image_name> -a
|
||||
```
|
||||
|
||||
@@ -144,11 +144,11 @@ To pull an image to [Docker Hub](https://hub.docker.com/):
|
||||
### Inspect and pull an image with GHCR
|
||||
|
||||
* Inspect the docker image
|
||||
* ```
|
||||
```
|
||||
docker inspect ghcr.io/<repository>/<image>:<tag>
|
||||
```
|
||||
* Pull the docker image
|
||||
* ```
|
||||
```
|
||||
docker pull ghcr.io/<repository>/<image>:<tag>
|
||||
```
|
||||
|
||||
@@ -174,20 +174,20 @@ To install Skopeo, read [this documentation](install.md).
|
||||
Use **docker build** to build a container based on a Dockerfile
|
||||
|
||||
* Build a container based on current directory Dockerfile
|
||||
* ```
|
||||
```
|
||||
docker build .
|
||||
```
|
||||
* Build a container and store the image with a given name
|
||||
* Template
|
||||
* ```
|
||||
```
|
||||
docker build -t "<image_name>:<tag>"
|
||||
```
|
||||
* Example
|
||||
* ```
|
||||
```
|
||||
docker build -t newimage:latest
|
||||
```
|
||||
* Build a docker container without using the cache
|
||||
* ```
|
||||
```
|
||||
docker build --no-cache
|
||||
```
|
||||
|
||||
@@ -206,15 +206,15 @@ docker images
|
||||
To run a container based on an image, use the command **docker run**.
|
||||
|
||||
* Run an image
|
||||
* ```
|
||||
```
|
||||
docker run <image_name>
|
||||
```
|
||||
* Run an image in the background (run and detach)
|
||||
* ```
|
||||
```
|
||||
docker run -d <image_name>
|
||||
```
|
||||
* Run an image with CLI input
|
||||
* ```
|
||||
```
|
||||
docker run -it <image_name>
|
||||
```
|
||||
|
||||
@@ -229,7 +229,7 @@ You can also specify the shell, e.g. **docker run -it <image_name> /bin/bash**
|
||||
To run a new command in an existing container, use **docker exec**.
|
||||
|
||||
* Execute interactive shell on the container
|
||||
* ```
|
||||
```
|
||||
docker exec -it <container_name> sh
|
||||
```
|
||||
|
||||
@@ -238,11 +238,11 @@ To run a new command in an existing container, use **docker exec**.
|
||||
### Bash shell into container
|
||||
|
||||
* Bash shell into a container
|
||||
* ```
|
||||
```
|
||||
docker exec -i -t /bin/bash
|
||||
```
|
||||
* Bash shell into a container with root
|
||||
* ```
|
||||
```
|
||||
docker exec -i -t -u root /bin/bash
|
||||
```
|
||||
|
||||
@@ -300,22 +300,22 @@ docker cp <container_id>:<file_path> <file_path_destination>
|
||||
### Delete all the containers, images and volumes
|
||||
|
||||
* To delete all containers:
|
||||
* ```
|
||||
```
|
||||
docker compose rm -f -s -v
|
||||
```
|
||||
|
||||
* To delete all images:
|
||||
* ```
|
||||
```
|
||||
docker rmi -f $(docker images -aq)
|
||||
```
|
||||
|
||||
* To delete all volumes:
|
||||
* ```
|
||||
```
|
||||
docker volume rm $(docker volume ls -qf dangling=true)
|
||||
```
|
||||
|
||||
* To delete all containers, images and volumes:
|
||||
* ```
|
||||
```
|
||||
docker compose rm -f -s -v && docker rmi -f $(docker images -aq) && docker volume rm $(docker volume ls -qf dangling=true)
|
||||
```
|
||||
|
||||
@@ -324,7 +324,7 @@ docker cp <container_id>:<file_path> <file_path_destination>
|
||||
### Kill all the Docker processes
|
||||
|
||||
* To kill all processes:
|
||||
* ```
|
||||
```
|
||||
killall Docker && open /Applications/Docker.app
|
||||
```
|
||||
|
||||
@@ -353,11 +353,11 @@ docker ps -s
|
||||
### Examine disks usage
|
||||
|
||||
* Basic mode
|
||||
* ```
|
||||
```
|
||||
docker system df
|
||||
```
|
||||
* Verbose mode
|
||||
* ```
|
||||
```
|
||||
docker system df -v
|
||||
```
|
||||
|
||||
|
||||
@@ -33,14 +33,14 @@ Deploying on the TFGrid with tools such as the Playground and Terraform is easy
|
||||
### File transfer with IPv4
|
||||
|
||||
* From local to remote, write the following on the local terminal:
|
||||
* ```
|
||||
```
|
||||
scp <path_to_local_file>/<filename> <remote_username>@<remote_IPv4_address>:/<remote_username>/<path_to_remote_file>/<filename>
|
||||
```
|
||||
* From remote to local, you can write the following on the local terminal (more secure):
|
||||
* ```
|
||||
```
|
||||
scp <remote_username>@<remote_IPv4_address>:/<remote_username>/<path_to_remote_file>/<filename> <path_to_local_file>/<file>
|
||||
* From remote to local, you can also write the following on the remote terminal:
|
||||
* ```
|
||||
```
|
||||
scp <path_to_remote_file>/<file> <local_user>@<local_IPv4_address>:/<local_username>/<path_to_local_file>/<filename>
|
||||
|
||||
### File transfer with IPv6
|
||||
@@ -56,11 +56,11 @@ For IPv6, it is similar to IPv4 but you need to add `-6` after scp and add `\[`
|
||||
We show here how to transfer files between two computers. Note that at least one of the two computers must be local. This will transfer the content of the source directory into the destination directory.
|
||||
|
||||
* From local to remote
|
||||
* ```
|
||||
```
|
||||
rsync -avz --progress --delete /path/to/local/directory/ remote_user@<remote_host_or_ip>:/path/to/remote/directory
|
||||
```
|
||||
* From remote to local
|
||||
* ```
|
||||
```
|
||||
rsync -avz --progress --delete remote_user@<remote_host_or_ip>:/path/to/remote/directory/ /path/to/local/directory
|
||||
```
|
||||
|
||||
@@ -77,16 +77,16 @@ Here is short description of the parameters used:
|
||||
[rsync-sidekick](https://github.com/m-manu/rsync-sidekick) propagates changes from source directory to destination directory. You can run rsync-sidekick before running rsync. Make sure that [Go is installed](#install-go).
|
||||
|
||||
* Install rsync-sidekick
|
||||
* ```
|
||||
```
|
||||
sudo go install github.com/m-manu/rsync-sidekick@latest
|
||||
```
|
||||
* Reorganize the files and folders with rsync-sidekick
|
||||
* ```
|
||||
```
|
||||
rsync-sidekick /path/to/local/directory/ username@IP_Address:/path/to/remote/directory
|
||||
```
|
||||
|
||||
* Transfer and update files and folders with rsync
|
||||
* ```
|
||||
```
|
||||
sudo rsync -avz --progress --delete --log-file=/path/to/local/directory/rsync_storage.log /path/to/local/directory/ username@IP_Address:/path/to/remote/directory
|
||||
```
|
||||
|
||||
@@ -95,18 +95,18 @@ Here is short description of the parameters used:
|
||||
We show how to automate file transfers between two computers using rsync.
|
||||
|
||||
* Create the script file
|
||||
* ```
|
||||
```
|
||||
nano rsync_backup.sh
|
||||
```
|
||||
* Write the following script with the proper paths. Here the log is saved in the same directory.
|
||||
* ```
|
||||
```
|
||||
# filename: rsync_backup.sh
|
||||
#!/bin/bash
|
||||
|
||||
sudo rsync -avz --progress --delete --log-file=/path/to/local/directory/rsync_storage.log /path/to/local/directory/ username@IP_Address:/path/to/remote/directory
|
||||
```
|
||||
* Give permission
|
||||
* ```
|
||||
```
|
||||
sudo chmod +x /path/to/script/rsync_backup.sh
|
||||
```
|
||||
* Set a cron job to run the script periodically
|
||||
@@ -115,11 +115,11 @@ We show how to automate file transfers between two computers using rsync.
|
||||
sudo cp path/to/script/rsync_backup.sh /root
|
||||
```
|
||||
* Open the cron file
|
||||
* ```
|
||||
```
|
||||
sudo crontab -e
|
||||
```
|
||||
* Add the following to run the script everyday. For this example, we set the time at 18:00PM
|
||||
* ```
|
||||
```
|
||||
0 18 * * * /root/rsync_backup.sh
|
||||
```
|
||||
|
||||
@@ -128,11 +128,11 @@ We show how to automate file transfers between two computers using rsync.
|
||||
Depending on your situation, the parameters **--checksum** or **--ignore-times** can be quite useful. Note that adding either parameter will slow the transfer.
|
||||
|
||||
* With **--ignore time**, you ignore both the time and size of each file. This means that you transfer all files from source to destination.
|
||||
* ```
|
||||
```
|
||||
rsync --ignore-time source_folder/ destination_folder
|
||||
```
|
||||
* With **--checksum**, you verify with a checksum that the files from source and destination are the same. This means that you transfer all files that have a different checksum compared source to destination.
|
||||
* ```
|
||||
```
|
||||
rsync --checksum source_folder/ destination_folder
|
||||
```
|
||||
|
||||
@@ -141,11 +141,11 @@ Depending on your situation, the parameters **--checksum** or **--ignore-times**
|
||||
rsync does not act the same whether you use or not a slash ("\/") at the end of the source path.
|
||||
|
||||
* Copy content of **source_folder** into **destination_folder** to obtain the result: **destination_folder/source_folder_content**
|
||||
* ```
|
||||
```
|
||||
rsync source_folder/ destination_folder
|
||||
```
|
||||
* Copy **source_folder** into **destination_folder** to obtain the result: **destination_folder/source_folder/source_folder_content**
|
||||
* ```
|
||||
```
|
||||
rsync source_folder destination_folder
|
||||
```
|
||||
|
||||
|
||||
@@ -16,6 +16,12 @@
|
||||
- [Go to another branch](#go-to-another-branch)
|
||||
- [Add your changes to a local branch](#add-your-changes-to-a-local-branch)
|
||||
- [Push changes of a local branch to the remote Github branch](#push-changes-of-a-local-branch-to-the-remote-github-branch)
|
||||
- [Count the differences between two branches](#count-the-differences-between-two-branches)
|
||||
- [See the default branch](#see-the-default-branch)
|
||||
- [Force a push](#force-a-push)
|
||||
- [Merge a branch to a different branch](#merge-a-branch-to-a-different-branch)
|
||||
- [Clone completely one branch to another branch locally then push the changes to Github](#clone-completely-one-branch-to-another-branch-locally-then-push-the-changes-to-github)
|
||||
- [The 3 levels of the command reset](#the-3-levels-of-the-command-reset)
|
||||
- [Reverse modifications to a file where changes haven't been staged yet](#reverse-modifications-to-a-file-where-changes-havent-been-staged-yet)
|
||||
- [Download binaries from Github](#download-binaries-from-github)
|
||||
- [Resolve conflicts between branches](#resolve-conflicts-between-branches)
|
||||
@@ -50,11 +56,11 @@ You can install git on MAC, Windows and Linux. You can consult Git's documentati
|
||||
### Install on Linux
|
||||
|
||||
* Fedora distribution
|
||||
* ```
|
||||
```
|
||||
dnf install git-all
|
||||
```
|
||||
* Debian-based distribution
|
||||
* ```
|
||||
```
|
||||
apt install git-all
|
||||
```
|
||||
* Click [here](https://git-scm.com/download/linux) for other Linux distributions
|
||||
@@ -62,7 +68,7 @@ You can install git on MAC, Windows and Linux. You can consult Git's documentati
|
||||
### Install on MAC
|
||||
|
||||
* With Homebrew
|
||||
* ```
|
||||
```
|
||||
brew install git
|
||||
```
|
||||
|
||||
@@ -125,11 +131,11 @@ git checkout <branch_name>
|
||||
### Add your changes to a local branch
|
||||
|
||||
* Add all changes
|
||||
* ```
|
||||
```
|
||||
git add .
|
||||
```
|
||||
* Add changes of a specific file
|
||||
* ```
|
||||
```
|
||||
git add <path_to_file>/<file_name>
|
||||
```
|
||||
|
||||
@@ -139,13 +145,13 @@ git checkout <branch_name>
|
||||
|
||||
To push changes to Github, you can use the following commands:
|
||||
|
||||
* ```
|
||||
```
|
||||
git add .
|
||||
```
|
||||
* ```
|
||||
```
|
||||
git commit -m "write your changes here in comment"
|
||||
```
|
||||
* ```
|
||||
```
|
||||
git push
|
||||
```
|
||||
|
||||
@@ -178,15 +184,15 @@ git push --force
|
||||
### Merge a branch to a different branch
|
||||
|
||||
* Checkout the branch you want to copy content TO
|
||||
* ```
|
||||
```
|
||||
git checkout branch_name
|
||||
```
|
||||
* Merge the branch you want content FROM
|
||||
* ```
|
||||
```
|
||||
git merge origin/dev_mermaid
|
||||
```
|
||||
* Push the changes
|
||||
* ```
|
||||
```
|
||||
git push -u origin/head
|
||||
```
|
||||
|
||||
@@ -197,19 +203,19 @@ git push --force
|
||||
For this example, we copy **branchB** into **branchA**.
|
||||
|
||||
* See available branches
|
||||
* ```
|
||||
```
|
||||
git branch -r
|
||||
```
|
||||
* Go to **branchA**
|
||||
* ```
|
||||
```
|
||||
git checkout branchA
|
||||
```
|
||||
* Copy **branchB** into **branchA**
|
||||
* ```
|
||||
```
|
||||
git git reset --hard branchB
|
||||
```
|
||||
* Force the push
|
||||
* ```
|
||||
```
|
||||
git push --force
|
||||
```
|
||||
|
||||
@@ -217,17 +223,17 @@ For this example, we copy **branchB** into **branchA**.
|
||||
|
||||
### The 3 levels of the command reset
|
||||
|
||||
* ```
|
||||
```
|
||||
git reset --soft
|
||||
```
|
||||
* Bring the History to the Stage/Index
|
||||
* Discard last commit
|
||||
* ```
|
||||
```
|
||||
git reset --mixed
|
||||
```
|
||||
* Bring the History to the Working Directory
|
||||
* Discard last commit and add
|
||||
* ```
|
||||
```
|
||||
git reset --hard
|
||||
```
|
||||
* Bring the History to the Working Directory
|
||||
@@ -252,7 +258,7 @@ git checkout <filename>
|
||||
### Download binaries from Github
|
||||
|
||||
* Template:
|
||||
* ```
|
||||
```
|
||||
wget -O <file_name> https://raw.githubusercontent.com/<user_name>/<repository>/<path_to_file>/<file_name>
|
||||
```
|
||||
|
||||
@@ -263,29 +269,29 @@ git checkout <filename>
|
||||
We show how to resolve conflicts in a development branch (e.g. **branch_dev**) and then merging the development branch into the main branch (e.g. **branch_main**).
|
||||
|
||||
* Clone the repo
|
||||
* ```
|
||||
```
|
||||
git clone <repo_url>
|
||||
```
|
||||
* Pull changes and potential conflicts
|
||||
* ```
|
||||
```
|
||||
git pull origin branch_main
|
||||
```
|
||||
* Checkout the development branch
|
||||
* ```
|
||||
```
|
||||
git checkout branch_dev
|
||||
```
|
||||
* Resolve conflicts in a text editor
|
||||
* Save changes in the files
|
||||
* Add the changes
|
||||
* ```
|
||||
```
|
||||
git add .
|
||||
```
|
||||
* Commit the changes
|
||||
* ```
|
||||
```
|
||||
git commit -m "your message here"
|
||||
```
|
||||
* Push the changes
|
||||
* ```
|
||||
```
|
||||
git push
|
||||
```
|
||||
|
||||
@@ -294,11 +300,11 @@ We show how to resolve conflicts in a development branch (e.g. **branch_dev**) a
|
||||
### Download all repositories of an organization
|
||||
|
||||
* Log in to gh
|
||||
* ```
|
||||
```
|
||||
gh auth login
|
||||
```
|
||||
* Clone all repositories. Replace <organization> with the organization in question.
|
||||
* ```
|
||||
```
|
||||
gh repo list <organization> --limit 1000 | while read -r repo _; do
|
||||
gh repo clone "$repo" "$repo"
|
||||
done
|
||||
@@ -309,15 +315,15 @@ We show how to resolve conflicts in a development branch (e.g. **branch_dev**) a
|
||||
### Revert a push commited with git
|
||||
|
||||
* Find the commit ID
|
||||
* ```
|
||||
```
|
||||
git log -p
|
||||
```
|
||||
* Revert the commit
|
||||
* ```
|
||||
```
|
||||
git revert <commit_ID>
|
||||
```
|
||||
* Push the changes
|
||||
* ```
|
||||
```
|
||||
git push
|
||||
```
|
||||
|
||||
@@ -334,11 +340,11 @@ git clone -b <branch_name> --single-branch /<path_to_repo>/<repo_name>.git
|
||||
### Revert to a backup branch
|
||||
|
||||
* Checkout the branch you want to update (**branch**)
|
||||
* ```
|
||||
```
|
||||
git checkout <branch>
|
||||
```
|
||||
* Do a reset of your current branch based on the backup branch
|
||||
* ```
|
||||
```
|
||||
git reset --hard <backup_branch>
|
||||
```
|
||||
|
||||
@@ -363,19 +369,19 @@ Note that this will not work for untracked and new files. See below for untracke
|
||||
This method can be used to overwrite local files. This will work even if you have untracked and new files.
|
||||
|
||||
* Save local changes on a stash
|
||||
* ```
|
||||
```
|
||||
git stash --include-untracked
|
||||
```
|
||||
* Discard local changes
|
||||
* ```
|
||||
```
|
||||
git reset --hard
|
||||
```
|
||||
* Discard untracked and new files
|
||||
* ```
|
||||
```
|
||||
git clean -fd
|
||||
```
|
||||
* Pull the remote branch
|
||||
* ```
|
||||
```
|
||||
git pull
|
||||
```
|
||||
|
||||
@@ -388,27 +394,27 @@ Then, to delete the stash, you can use **git stash drop**.
|
||||
The stash command is used to record the current state of the working directory.
|
||||
|
||||
* Stash a branch (equivalent to **git stash push**)
|
||||
* ```
|
||||
```
|
||||
git stash
|
||||
```
|
||||
* List the changes in the stash
|
||||
* ```
|
||||
```
|
||||
git stash list
|
||||
```
|
||||
* Inspect the changes in the stash
|
||||
* ```
|
||||
```
|
||||
git stash show
|
||||
```
|
||||
* Remove a single stashed state from the stash list and apply it on top of the current working tree state
|
||||
* ```
|
||||
```
|
||||
git stash pop
|
||||
```
|
||||
* Apply the stash on top of the current working tree state without removing the state from the stash list
|
||||
* ```
|
||||
```
|
||||
git stash apply
|
||||
```
|
||||
* Drop a stash
|
||||
* ```
|
||||
```
|
||||
git stash drop
|
||||
```
|
||||
|
||||
@@ -431,15 +437,15 @@ To download VS-Code, visit their website and follow the given instructions.
|
||||
There are many ways to install VS-Codium. Visit the [official website](https://vscodium.com/#install) for more information.
|
||||
|
||||
* Install on MAC
|
||||
* ```
|
||||
```
|
||||
brew install --cask vscodium
|
||||
```
|
||||
* Install on Linux
|
||||
* ```
|
||||
```
|
||||
snap install codium --classic
|
||||
```
|
||||
* Install on Windows
|
||||
* ```
|
||||
```
|
||||
choco install vscodium
|
||||
```
|
||||
|
||||
|
||||
@@ -34,53 +34,50 @@ To start, you must [deploy and SSH into a full VM](ssh_guide.md).
|
||||
* With an IPv4 Address
|
||||
* After deployment, copy the IPv4 address
|
||||
* Connect into the VM via SSH
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_address
|
||||
```
|
||||
* Create a new user with root access
|
||||
* Here we use `newuser` as an example
|
||||
* ```
|
||||
adduser newuser
|
||||
```
|
||||
```
|
||||
adduser newuser
|
||||
```
|
||||
* To see the directory of the new user
|
||||
* ```
|
||||
ls /home
|
||||
```
|
||||
```
|
||||
ls /home
|
||||
```
|
||||
* Give sudo capacity to the new user
|
||||
* ```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
* Make the new user accessible by SSH
|
||||
* ```
|
||||
su - newuser
|
||||
```
|
||||
* ```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
* ```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* add the authorized public key in the file, then save and quit
|
||||
* Exit the VM and reconnect with the new user
|
||||
* ```
|
||||
exit
|
||||
```
|
||||
* ```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
```
|
||||
su - newuser
|
||||
mkdir ~/.ssh
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* Add the authorized public key in the file, then save and quit
|
||||
* Exit the VM
|
||||
```
|
||||
exit
|
||||
```
|
||||
* Reconnect with the new user
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Set the VM and Install Cockpit
|
||||
|
||||
* Update and upgrade the VM
|
||||
* ```
|
||||
sudo apt update -y && sudo apt upgrade -y && sudo apt-get update -y
|
||||
```
|
||||
```
|
||||
sudo apt update -y && sudo apt upgrade -y && sudo apt-get update -y
|
||||
```
|
||||
* Install Cockpit
|
||||
* ```
|
||||
. /etc/os-release && sudo apt install -t ${UBUNTU_CODENAME}-backports cockpit -y
|
||||
```
|
||||
```
|
||||
. /etc/os-release && sudo apt install -t ${UBUNTU_CODENAME}-backports cockpit -y
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -89,47 +86,47 @@ To start, you must [deploy and SSH into a full VM](ssh_guide.md).
|
||||
We now change the system daemon that manages network configurations. We will be using [NetworkManager](https://networkmanager.dev/) instead of [networkd](https://wiki.archlinux.org/title/systemd-networkd). This will give us further possibilities on Cockpit.
|
||||
|
||||
* Install NetworkManager. Note that it might already be installed.
|
||||
* ```
|
||||
```
|
||||
sudo apt install network-manager -y
|
||||
```
|
||||
* Update the `.yaml` file
|
||||
* Go to netplan's directory
|
||||
* ```
|
||||
cd /etc/netplan
|
||||
```
|
||||
```
|
||||
cd /etc/netplan
|
||||
```
|
||||
* Search for the proper `.yaml` file name
|
||||
* ```
|
||||
ls -l
|
||||
```
|
||||
```
|
||||
ls -l
|
||||
```
|
||||
* Update the `.yaml` file
|
||||
* ```
|
||||
sudo nano 50-cloud-init.yaml
|
||||
```
|
||||
```
|
||||
sudo nano 50-cloud-init.yaml
|
||||
```
|
||||
* Add the following lines under `network:`
|
||||
* ```
|
||||
version: 2
|
||||
renderer: NetworkManager
|
||||
```
|
||||
* Note that these two lines should be aligned with `ethernets:`
|
||||
```
|
||||
version: 2
|
||||
renderer: NetworkManager
|
||||
```
|
||||
* Note that these two lines should be aligned with `ethernets:`
|
||||
* Remove `version: 2` at the bottom of the file
|
||||
* Save and exit the file
|
||||
* Disable networkd and enable NetworkManager
|
||||
* ```
|
||||
```
|
||||
sudo systemctl disable systemd-networkd
|
||||
```
|
||||
* ```
|
||||
```
|
||||
sudo systemctl enable NetworkManager
|
||||
```
|
||||
* Apply netplan to set NetworkManager
|
||||
* ```
|
||||
```
|
||||
sudo netplan apply
|
||||
```
|
||||
* Reboot the system to load the new kernel and to properly set NetworkManager
|
||||
* ```
|
||||
```
|
||||
sudo reboot
|
||||
```
|
||||
* Reconnect to the VM
|
||||
* ```
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
|
||||
@@ -139,24 +136,24 @@ We now change the system daemon that manages network configurations. We will be
|
||||
We now set a firewall. We note that [ufw](https://wiki.ubuntu.com/UncomplicatedFirewall) is not compatible with Cockpit and for this reason, we will be using [firewalld](https://firewalld.org/).
|
||||
|
||||
* Install firewalld
|
||||
* ```
|
||||
```
|
||||
sudo apt install firewalld -y
|
||||
```
|
||||
|
||||
* Add Cockpit to firewalld
|
||||
* ```
|
||||
```
|
||||
sudo firewall-cmd --add-service=cockpit
|
||||
```
|
||||
* ```
|
||||
```
|
||||
sudo firewall-cmd --add-service=cockpit --permanent
|
||||
```
|
||||
* See if Cockpit is available
|
||||
* ```
|
||||
```
|
||||
sudo firewall-cmd --info-service=cockpit
|
||||
```
|
||||
|
||||
* See the status of firewalld
|
||||
* ```
|
||||
```
|
||||
sudo firewall-cmd --state
|
||||
```
|
||||
|
||||
@@ -165,7 +162,7 @@ We now set a firewall. We note that [ufw](https://wiki.ubuntu.com/UncomplicatedF
|
||||
## Access Cockpit
|
||||
|
||||
* On your web browser, write the following URL with the proper VM IPv4 address
|
||||
* ```
|
||||
```
|
||||
VM_IPv4_Address:9090
|
||||
```
|
||||
* Enter the username and password of the root-access user
|
||||
|
||||
@@ -37,30 +37,30 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
* Minimum storage: 15Gb
|
||||
* After deployment, note the VM IPv4 address
|
||||
* Connect to the VM via SSH
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_address
|
||||
```
|
||||
* Once connected, create a new user with root access (for this guide we use "newuser")
|
||||
* ```
|
||||
```
|
||||
adduser newuser
|
||||
```
|
||||
* You should now see the new user directory
|
||||
* ```
|
||||
```
|
||||
ls /home
|
||||
```
|
||||
* Give sudo capacity to the new user
|
||||
* ```
|
||||
```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
* Make the new user accessible by SSH
|
||||
* ```
|
||||
```
|
||||
su - newuser
|
||||
```
|
||||
* ```
|
||||
```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
* Add authorized public key in the file and save it
|
||||
* ```
|
||||
```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* Exit the VM and reconnect with the new user
|
||||
@@ -70,21 +70,21 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
## SSH with Root-Access User, Install Prerequisites and Apache Guacamole
|
||||
|
||||
* SSH into the VM
|
||||
* ```
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
* Update and upgrade Ubuntu
|
||||
* ```
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y && sudo apt-get install software-properties-common -y
|
||||
```
|
||||
* Download and run Apache Guacamole
|
||||
* ```
|
||||
```
|
||||
wget -O guac-install.sh https://git.io/fxZq5
|
||||
```
|
||||
* ```
|
||||
```
|
||||
chmod +x guac-install.sh
|
||||
```
|
||||
* ```
|
||||
```
|
||||
sudo ./guac-install.sh
|
||||
```
|
||||
|
||||
@@ -93,11 +93,11 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
## Access Apache Guacamole and Create Admin-Access User
|
||||
|
||||
* On your local computer, open a browser and write the following URL with the proper IPv4 address
|
||||
* ```
|
||||
```
|
||||
https://VM_IPv4_address:8080/guacamole
|
||||
```
|
||||
* On Guacamole, enter the following for both the username and the password
|
||||
* ```
|
||||
```
|
||||
guacadmin
|
||||
```
|
||||
* Download the [TOTP](https://totp.app/) app on your Android or iOS
|
||||
@@ -120,23 +120,23 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
## Download the Desktop Environment and Run xrdp
|
||||
|
||||
* Download a Ubuntu desktop environment on the VM
|
||||
* ```
|
||||
sudo apt install tasksel -y && sudo apt install lightdm -y
|
||||
```
|
||||
* Choose lightdm
|
||||
```
|
||||
sudo apt install tasksel -y && sudo apt install lightdm -y
|
||||
```
|
||||
* Choose lightdm
|
||||
* Run tasksel and choose `ubuntu desktop`
|
||||
* ```
|
||||
sudo tasksel
|
||||
```
|
||||
```
|
||||
sudo tasksel
|
||||
```
|
||||
|
||||
* Download and run xrdp
|
||||
* ```
|
||||
```
|
||||
wget https://c-nergy.be/downloads/xRDP/xrdp-installer-1.4.6.zip
|
||||
```
|
||||
* ```
|
||||
```
|
||||
unzip xrdp-installer-1.4.6.zip
|
||||
```
|
||||
* ```
|
||||
```
|
||||
bash xrdp-installer-1.4.6.sh
|
||||
```
|
||||
|
||||
@@ -146,7 +146,7 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
|
||||
* Create an RDP connection on Guacamole
|
||||
* Open Guacamole
|
||||
* ```
|
||||
```
|
||||
http://VM_IPv4_address:8080/guacamole/
|
||||
```
|
||||
* Go to Settings
|
||||
|
||||
@@ -31,109 +31,109 @@ If you are new to the Threefold ecosystem and you want to deploy workloads on th
|
||||
* With an IPv4 Address
|
||||
* After deployment, copy the IPv4 address
|
||||
* To SSH into the VM, write in the terminal
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_address
|
||||
```
|
||||
* Once connected, update, upgrade and install the desktop environment
|
||||
* Update
|
||||
* ```
|
||||
sudo apt update -y && sudo apt upgrade -y
|
||||
```
|
||||
```
|
||||
sudo apt update -y && sudo apt upgrade -y
|
||||
```
|
||||
* Install a light-weight desktop environment (Xfce)
|
||||
* ```
|
||||
sudo apt install xfce4 xfce4-goodies -y
|
||||
```
|
||||
```
|
||||
sudo apt install xfce4 xfce4-goodies -y
|
||||
```
|
||||
* Create a user with root access
|
||||
* ```
|
||||
adduser newuser
|
||||
```
|
||||
* ```
|
||||
ls /home
|
||||
```
|
||||
* You should see the newuser directory
|
||||
```
|
||||
adduser newuser
|
||||
```
|
||||
```
|
||||
ls /home
|
||||
```
|
||||
* You should see the newuser directory
|
||||
* Give sudo capacity to newuser
|
||||
* ```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
```
|
||||
usermod -aG sudo newuser
|
||||
```
|
||||
* Make newuser accessible by SSH
|
||||
* ```
|
||||
su - newuser
|
||||
```
|
||||
* ```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
* ```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* add authorized public key in file and save
|
||||
```
|
||||
su - newuser
|
||||
```
|
||||
```
|
||||
mkdir ~/.ssh
|
||||
```
|
||||
```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
* add authorized public key in file and save
|
||||
* Exit the VM and reconnect with new user
|
||||
* ```
|
||||
exit
|
||||
```
|
||||
```
|
||||
exit
|
||||
```
|
||||
* Reconnect to the VM terminal and install XRDP
|
||||
* ```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
```
|
||||
ssh newuser@VM_IPv4_address
|
||||
```
|
||||
* Install XRDP
|
||||
* ```
|
||||
```
|
||||
sudo apt install xrdp -y
|
||||
```
|
||||
* Check XRDP status
|
||||
* ```
|
||||
```
|
||||
sudo systemctl status xrdp
|
||||
```
|
||||
* If not running, run manually:
|
||||
* ```
|
||||
sudo systemctl start xrdp
|
||||
```
|
||||
```
|
||||
sudo systemctl start xrdp
|
||||
```
|
||||
* If needed, configure xrdp (optional)
|
||||
* ```
|
||||
```
|
||||
sudo nano /etc/xrdp/xrdp.ini
|
||||
```
|
||||
* Create a session with root-access user
|
||||
Move to home directory
|
||||
* Go to home directory of root-access user
|
||||
* ```
|
||||
cd ~
|
||||
```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
* Create session
|
||||
* ```
|
||||
```
|
||||
echo "xfce4-session" | tee .xsession
|
||||
```
|
||||
* Restart the server
|
||||
* ```
|
||||
```
|
||||
sudo systemctl restart xrdp
|
||||
```
|
||||
|
||||
* Find your local computer IP address
|
||||
* On your local computer terminal, write
|
||||
* ```
|
||||
curl ifconfig.me
|
||||
```
|
||||
```
|
||||
curl ifconfig.me
|
||||
```
|
||||
|
||||
* On the VM terminal, allow client computer port to the firewall (ufw)
|
||||
* ```
|
||||
```
|
||||
sudo ufw allow from your_local_ip/32 to any port 3389
|
||||
```
|
||||
* Allow SSH connection to your firewall
|
||||
* ```
|
||||
```
|
||||
sudo ufw allow ssh
|
||||
```
|
||||
* Verify status of the firewall
|
||||
* ```
|
||||
```
|
||||
sudo ufw status
|
||||
```
|
||||
* If not active, do the following:
|
||||
* ```
|
||||
sudo ufw disable
|
||||
```
|
||||
* ```
|
||||
sudo ufw enable
|
||||
```
|
||||
```
|
||||
sudo ufw disable
|
||||
```
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
* Then the ufw status should show changes
|
||||
* ```
|
||||
sudo ufw status
|
||||
```
|
||||
```
|
||||
sudo ufw status
|
||||
```
|
||||
|
||||
|
||||
## Client Side: Install Remote Desktop Connection for Windows, MAC or Linux
|
||||
@@ -149,7 +149,7 @@ Simply download the app, open it and write the IPv4 address of the VM. You then
|
||||
* [Remote Desktop Connection app](https://apps.microsoft.com/store/detail/microsoft-remote-desktop/9WZDNCRFJ3PS?hl=en-ca&gl=ca&rtc=1)
|
||||
* MAC
|
||||
* Download in app store
|
||||
* [Microsoft Remote Desktop Connection app](https://apps.apple.com/ca/app/microsoft-remote-desktop/id1295203466?mt=12)
|
||||
* [Microsoft Remote Desktop Connection app](https://apps.apple.com/ca/app/microsoft-remote-desktop/id1295203466?mt=12)
|
||||
* Linux
|
||||
* [Remmina RDP Client](https://remmina.org/)
|
||||
|
||||
|
||||
@@ -50,13 +50,13 @@ The main steps for the whole process are the following:
|
||||
Here are the steps to SSH into a 3Node with IPv4 on Linux.
|
||||
|
||||
* To create the SSH key pair, write in the terminal
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in the terminal
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -72,7 +72,7 @@ Here are the steps to SSH into a 3Node with IPv4 on Linux.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the IPv4 address
|
||||
* Open the terminal, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@IPv4_address
|
||||
```
|
||||
|
||||
@@ -92,13 +92,13 @@ Here are the steps to SSH into a 3Node with the Planetary Network on Linux.
|
||||
* Disconnect your VPN if you have one
|
||||
* In the connector, click `Connect`
|
||||
* To create the SSH key pair, write in the terminal
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in the terminal
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -114,7 +114,7 @@ Here are the steps to SSH into a 3Node with the Planetary Network on Linux.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the Planetary Network address
|
||||
* Open the terminal, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@planetary_network_address
|
||||
```
|
||||
|
||||
@@ -129,13 +129,13 @@ You now have an SSH connection on Linux with the Planetary Network.
|
||||
Here are the steps to SSH into a 3Node with IPv4 on MAC.
|
||||
|
||||
* To create the SSH key pair, in the terminal write
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in the terminal
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -151,7 +151,7 @@ Here are the steps to SSH into a 3Node with IPv4 on MAC.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the IPv4 address
|
||||
* Open the terminal, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@IPv4_address
|
||||
```
|
||||
|
||||
@@ -170,13 +170,13 @@ Here are the steps to SSH into a 3Node with the Planetary Network on MAC.
|
||||
* Disconnect your VPN if you have one
|
||||
* In the connector, click `Connect`
|
||||
* To create the SSH key pair, write in the terminal
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in the terminal
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -192,7 +192,7 @@ Here are the steps to SSH into a 3Node with the Planetary Network on MAC.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the Planetary Network address
|
||||
* Open the terminal, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@planetary_network_address
|
||||
```
|
||||
|
||||
@@ -214,13 +214,13 @@ You now have an SSH connection on MAC with the Planetary Network.
|
||||
* Search OpenSSH
|
||||
* Install OpenSSH Client and OpenSSH Server
|
||||
* To create the SSH key pair, open `PowerShell` and write
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in `PowerShell`
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -236,7 +236,7 @@ You now have an SSH connection on MAC with the Planetary Network.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the IPv4 address
|
||||
* Open `PowerShell`, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@IPv4_address
|
||||
```
|
||||
|
||||
@@ -262,13 +262,13 @@ You now have an SSH connection on Window with IPv4.
|
||||
* Search OpenSSH
|
||||
* Install OpenSSH Client and OpenSSH Server
|
||||
* To create the SSH key pair, open `PowerShell` and write
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Save in default location
|
||||
* Write a password (optional)
|
||||
* To see the public key, write in `PowerShell`
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Select and copy the public key when needed
|
||||
@@ -284,7 +284,7 @@ You now have an SSH connection on Window with IPv4.
|
||||
* To SSH into the VM once the 3Node is deployed
|
||||
* Copy the Planetary Network address
|
||||
* Open `PowerShell`, write the following with the deployment address and write **yes** to confirm
|
||||
* ```
|
||||
```
|
||||
ssh root@planetary_network_address
|
||||
```
|
||||
|
||||
|
||||
@@ -69,19 +69,19 @@ To set the WireGuard connection on Linux or MAC, create a WireGuard configuratio
|
||||
|
||||
* Copy the content **WireGuard Config** from the Dashboard **Details** window
|
||||
* Paste the content to a file with the extension `.conf` (e.g. **wg.conf**) in the directory `/etc/wireguard`
|
||||
* ```
|
||||
```
|
||||
sudo nano /etc/wireguard/wg.conf
|
||||
```
|
||||
* Start WireGuard with the command **wg-quick** and, as a parameter, pass the configuration file without the extension (e.g. *wg.conf -> wg*)
|
||||
* ```
|
||||
```
|
||||
wg-quick up wg
|
||||
```
|
||||
* Note that you can also specify a config file by path, stored in any location
|
||||
* ```
|
||||
```
|
||||
wg-quick up /etc/wireguard/wg.conf
|
||||
```
|
||||
* If you want to stop the WireGuard service, you can write the following in the terminal
|
||||
* ```
|
||||
```
|
||||
wg-quick down wg
|
||||
```
|
||||
|
||||
@@ -105,7 +105,7 @@ To set the WireGuard connection on Windows, add and activate a tunnel with the W
|
||||
As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the virtual IP address of the VM to make sure the WireGuard connection is properly established. Make sure to replace `VM_WireGuard_IP` with the proper WireGuard IP address:
|
||||
|
||||
* Ping the deployment
|
||||
* ```
|
||||
```
|
||||
ping VM_WireGuard_IP
|
||||
```
|
||||
|
||||
@@ -116,7 +116,7 @@ As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-th
|
||||
To SSH into the deployment with Wireguard, use the **WireGuard IP** shown in the Dashboard **Details** window.
|
||||
|
||||
* SSH into the deployment
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_WireGuard_IP
|
||||
```
|
||||
|
||||
|
||||
@@ -25,11 +25,11 @@ There are a few things to set up before exploring Pulumi. Since we will be using
|
||||
|
||||
* [Install Pulumi](pulumi_install.md) on your machine
|
||||
* Clone the **Pulumi-ThreeFold** repository
|
||||
* ```
|
||||
```
|
||||
git clone https://github.com/threefoldtech/pulumi-threefold
|
||||
```
|
||||
* Change directory
|
||||
* ```
|
||||
```
|
||||
cd ./pulumi-threefold
|
||||
```
|
||||
|
||||
@@ -38,15 +38,15 @@ There are a few things to set up before exploring Pulumi. Since we will be using
|
||||
You can export the environment variables before deploying workloads.
|
||||
|
||||
* Export the network (**dev**, **qa**, **test**, **main**). Note that we are using the **dev** network by default.
|
||||
* ```
|
||||
```
|
||||
export NETWORK="Enter the network"
|
||||
```
|
||||
* Export your mnemonics.
|
||||
* ```
|
||||
```
|
||||
export MNEMONIC="Enter the mnemonics"
|
||||
```
|
||||
* Export the SSH_KEY (public key).
|
||||
* ```
|
||||
```
|
||||
export SSH_KEY="Enter the public Key"
|
||||
```
|
||||
|
||||
@@ -65,11 +65,11 @@ The different examples that work simply by running **make run** are the followin
|
||||
We give an example with **virtual_machine**.
|
||||
|
||||
* Go to the directory **virtual_machine**
|
||||
* ```
|
||||
```
|
||||
cd examples/virtual_machine
|
||||
```
|
||||
* Deploy the Pulumi workload with **make**
|
||||
* ```
|
||||
```
|
||||
make run
|
||||
```
|
||||
|
||||
|
||||
@@ -17,15 +17,15 @@ To install Pulumi, simply follow the steps provided in the [Pulumi documentation
|
||||
## Installation
|
||||
|
||||
* Install on Linux
|
||||
* ```
|
||||
```
|
||||
curl -fsSL https://get.pulumi.com | sh
|
||||
```
|
||||
* Install on MAC
|
||||
* ```
|
||||
```
|
||||
brew install pulumi/tap/pulumi
|
||||
```
|
||||
* Install on Windows
|
||||
* ```
|
||||
```
|
||||
choco install pulumi
|
||||
```
|
||||
|
||||
|
||||
@@ -102,19 +102,19 @@ Modify the variable files to take into account your own seed phras and SSH keys.
|
||||
Open the terminal.
|
||||
|
||||
* Go to the home folder
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-synced-db`:
|
||||
* ```
|
||||
```
|
||||
mkdir -p terraform/deployment-synced-db
|
||||
```
|
||||
* ```
|
||||
```
|
||||
cd terraform/deployment-synced-db
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -259,12 +259,12 @@ In this file, we name the first VM as `vm1` and the second VM as `vm2`. For ease
|
||||
In this guide, the virtual IP for `vm1` is 10.1.3.2 and the virtual IP for `vm2`is 10.1.4.2. This might be different during your own deployment. If so, change the codes in this guide accordingly.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file.
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -285,19 +285,19 @@ Make sure to add your own seed phrase and SSH public key. You will also need to
|
||||
We now deploy the VPN with Terraform. Make sure that you are in the correct folder `terraform/deployment-synced-db` with the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy the VPN:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
After deployments, take note of the 3Nodes' IPv4 address. You will need those addresses to SSH into the 3Nodes.
|
||||
|
||||
Note that, at any moment, if you want to see the information on your Terraform deployments, write the following:
|
||||
* ```
|
||||
```
|
||||
terraform show
|
||||
```
|
||||
|
||||
@@ -306,7 +306,7 @@ Note that, at any moment, if you want to see the information on your Terraform d
|
||||
### SSH into the 3Nodes
|
||||
|
||||
* To [SSH into the 3Nodes](ssh_guide.md), write the following while making sure to set the proper IP address for each VM:
|
||||
* ```
|
||||
```
|
||||
ssh root@3node_IPv4_Address
|
||||
```
|
||||
|
||||
@@ -315,11 +315,11 @@ Note that, at any moment, if you want to see the information on your Terraform d
|
||||
### Preparing the VMs for the Deployment
|
||||
|
||||
* Update and upgrade the system
|
||||
* ```
|
||||
```
|
||||
apt update && sudo apt upgrade -y && sudo apt-get install apache2 -y
|
||||
```
|
||||
* After download, you might need to reboot the system for changes to be fully taken into account
|
||||
* ```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
* Reconnect to the VMs
|
||||
@@ -333,19 +333,19 @@ We now want to ping the VMs using Wireguard. This will ensure the connection is
|
||||
First, we set Wireguard with the Terraform output.
|
||||
|
||||
* On your local computer, take the Terraform's `wg_config` output and create a `wg.conf` file in the directory `/usr/local/etc/wireguard/wg.conf`.
|
||||
* ```
|
||||
```
|
||||
nano /usr/local/etc/wireguard/wg.conf
|
||||
```
|
||||
|
||||
* Paste the content provided by the Terraform deployment. You can use `terraform show` to see the Terraform output. The WireGuard output stands in between `EOT`.
|
||||
|
||||
* Start the WireGuard on your local computer:
|
||||
* ```
|
||||
```
|
||||
wg-quick up wg
|
||||
```
|
||||
|
||||
* To stop the wireguard service:
|
||||
* ```
|
||||
```
|
||||
wg-quick down wg
|
||||
```
|
||||
|
||||
@@ -353,10 +353,10 @@ First, we set Wireguard with the Terraform output.
|
||||
This should set everything properly.
|
||||
|
||||
* As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the virtual IP addresses of both VMs to make sure the Wireguard connection is correct:
|
||||
* ```
|
||||
```
|
||||
ping 10.1.3.2
|
||||
```
|
||||
* ```
|
||||
```
|
||||
ping 10.1.4.2
|
||||
```
|
||||
|
||||
@@ -371,11 +371,11 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
## Download MariaDB and Configure the Database
|
||||
|
||||
* Download the MariaDB server and client on both the master VM and the worker VM
|
||||
* ```
|
||||
```
|
||||
apt install mariadb-server mariadb-client -y
|
||||
```
|
||||
* Configure the MariaDB database
|
||||
* ```
|
||||
```
|
||||
nano /etc/mysql/mariadb.conf.d/50-server.cnf
|
||||
```
|
||||
* Do the following changes
|
||||
@@ -392,12 +392,12 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
```
|
||||
|
||||
* Restart MariaDB
|
||||
* ```
|
||||
```
|
||||
systemctl restart mysql
|
||||
```
|
||||
|
||||
* Launch Mariadb
|
||||
* ```
|
||||
```
|
||||
mysql
|
||||
```
|
||||
|
||||
@@ -406,7 +406,7 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
## Create User with Replication Grant
|
||||
|
||||
* Do the following on both the master and the worker
|
||||
* ```
|
||||
```
|
||||
CREATE USER 'repuser'@'%' IDENTIFIED BY 'password';
|
||||
GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'%' ;
|
||||
FLUSH PRIVILEGES;
|
||||
@@ -429,17 +429,17 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
### TF Template Worker Server Data
|
||||
|
||||
* Write the following in the Worker VM
|
||||
* ```
|
||||
```
|
||||
CHANGE MASTER TO MASTER_HOST='10.1.3.2',
|
||||
MASTER_USER='repuser',
|
||||
MASTER_PASSWORD='password',
|
||||
MASTER_LOG_FILE='mysql-bin.000001',
|
||||
MASTER_LOG_POS=328;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
start slave;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
show slave status\G;
|
||||
```
|
||||
|
||||
@@ -448,17 +448,17 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
### TF Template Master Server Data
|
||||
|
||||
* Write the following in the Master VM
|
||||
* ```
|
||||
```
|
||||
CHANGE MASTER TO MASTER_HOST='10.1.4.2',
|
||||
MASTER_USER='repuser',
|
||||
MASTER_PASSWORD='password',
|
||||
MASTER_LOG_FILE='mysql-bin.000001',
|
||||
MASTER_LOG_POS=328;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
start slave;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
show slave status\G;
|
||||
```
|
||||
|
||||
@@ -503,71 +503,71 @@ We now set the MariaDB database. You should choose your own username and passwor
|
||||
We will now install and set [GlusterFS](https://www.gluster.org/), a free and open-source software scalable network filesystem.
|
||||
|
||||
* Install GlusterFS on both the master and worker VMs
|
||||
* ```
|
||||
```
|
||||
add-apt-repository ppa:gluster/glusterfs-7 -y && apt install glusterfs-server -y
|
||||
```
|
||||
* Start the GlusterFS service on both VMs
|
||||
* ```
|
||||
```
|
||||
systemctl start glusterd.service && systemctl enable glusterd.service
|
||||
```
|
||||
* Set the master to worker probe IP on the master VM:
|
||||
* ```
|
||||
```
|
||||
gluster peer probe 10.1.4.2
|
||||
```
|
||||
|
||||
* See the peer status on the worker VM:
|
||||
* ```
|
||||
```
|
||||
gluster peer status
|
||||
```
|
||||
|
||||
* Set the master and worker IP address on the master VM:
|
||||
* ```
|
||||
```
|
||||
gluster volume create vol1 replica 2 10.1.3.2:/gluster-storage 10.1.4.2:/gluster-storage force
|
||||
```
|
||||
|
||||
* Start Gluster:
|
||||
* ```
|
||||
```
|
||||
gluster volume start vol1
|
||||
```
|
||||
|
||||
* Check the status on the worker VM:
|
||||
* ```
|
||||
```
|
||||
gluster volume status
|
||||
```
|
||||
|
||||
* Mount the server with the master IP on the master VM:
|
||||
* ```
|
||||
```
|
||||
mount -t glusterfs 10.1.3.2:/vol1 /var/www
|
||||
```
|
||||
|
||||
* See if the mount is there on the master VM:
|
||||
* ```
|
||||
```
|
||||
df -h
|
||||
```
|
||||
|
||||
* Mount the Server with the worker IP on the worker VM:
|
||||
* ```
|
||||
```
|
||||
mount -t glusterfs 10.1.4.2:/vol1 /var/www
|
||||
```
|
||||
|
||||
* See if the mount is there on the worker VM:
|
||||
* ```
|
||||
```
|
||||
df -h
|
||||
```
|
||||
|
||||
We now update the mount with the filse fstab on both master and worker.
|
||||
|
||||
* To prevent the mount from being aborted if the server reboot, write the following on both servers:
|
||||
* ```
|
||||
```
|
||||
nano /etc/fstab
|
||||
```
|
||||
* Add the following line in the `fstab` file to set the master VM with the master virtual IP (here it is 10.1.3.2):
|
||||
* ```
|
||||
```
|
||||
10.1.3.2:/vol1 /var/www glusterfs defaults,_netdev 0 0
|
||||
```
|
||||
|
||||
* Add the following line in the `fstab` file to set the worker VM with the worker virtual IP (here it is 10.1.4.2):
|
||||
* ```
|
||||
```
|
||||
10.1.4.2:/vol1 /var/www glusterfs defaults,_netdev 0 0
|
||||
```
|
||||
|
||||
|
||||
@@ -46,33 +46,33 @@ For our security rules, we want to allow SSH, HTTP and HTTPS (443 and 8443).
|
||||
We thus add the following rules:
|
||||
|
||||
* Allow SSH (port 22)
|
||||
* ```
|
||||
```
|
||||
ufw allow ssh
|
||||
```
|
||||
* Allow HTTP (port 80)
|
||||
* ```
|
||||
```
|
||||
ufw allow http
|
||||
```
|
||||
* Allow https (port 443)
|
||||
* ```
|
||||
```
|
||||
ufw allow https
|
||||
```
|
||||
* Allow port 8443
|
||||
* ```
|
||||
```
|
||||
ufw allow 8443
|
||||
```
|
||||
* Allow port 3478 for Nextcloud Talk
|
||||
* ```
|
||||
```
|
||||
ufw allow 3478
|
||||
```
|
||||
|
||||
* To enable the firewall, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
* To see the current security rules, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw status verbose
|
||||
```
|
||||
|
||||
@@ -90,7 +90,7 @@ You now have enabled the firewall with proper security rules for your Nextcloud
|
||||
* TTL: Automatic
|
||||
* It might take up to 30 minutes to set the DNS properly.
|
||||
* To check if the A record has been registered, you can use a common DNS checker:
|
||||
* ```
|
||||
```
|
||||
https://dnschecker.org/#A/<domain-name>
|
||||
```
|
||||
|
||||
@@ -101,11 +101,11 @@ You now have enabled the firewall with proper security rules for your Nextcloud
|
||||
For the rest of the guide, we follow the steps availabe on the Nextcloud website's tutorial [How to Install the Nextcloud All-in-One on Linux](https://nextcloud.com/blog/how-to-install-the-nextcloud-all-in-one-on-linux/).
|
||||
|
||||
* Install Docker
|
||||
* ```
|
||||
```
|
||||
curl -fsSL get.docker.com | sudo sh
|
||||
```
|
||||
* Install Nextcloud AIO
|
||||
* ```
|
||||
```
|
||||
sudo docker run \
|
||||
--sig-proxy=false \
|
||||
--name nextcloud-aio-mastercontainer \
|
||||
@@ -118,7 +118,7 @@ For the rest of the guide, we follow the steps availabe on the Nextcloud website
|
||||
nextcloud/all-in-one:latest
|
||||
```
|
||||
* Reach the AIO interface on your browser:
|
||||
* ```
|
||||
```
|
||||
https://<domain_name>:8443
|
||||
```
|
||||
* Example: `https://nextcloudwebsite.com:8443`
|
||||
|
||||
@@ -126,19 +126,19 @@ Modify the variable files to take into account your own seed phrase and SSH keys
|
||||
Open the terminal.
|
||||
|
||||
* Go to the home folder
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-nextcloud`:
|
||||
* ```
|
||||
```
|
||||
mkdir -p terraform/deployment-nextcloud
|
||||
```
|
||||
* ```
|
||||
```
|
||||
cd terraform/deployment-nextcloud
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -283,12 +283,12 @@ In this file, we name the first VM as `vm1` and the second VM as `vm2`. In the g
|
||||
In this guide, the virtual IP for `vm1` is 10.1.3.2 and the virtual IP for `vm2` is 10.1.4.2. This might be different during your own deployment. Change the codes in this guide accordingly.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file.
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -307,12 +307,12 @@ Make sure to add your own seed phrase and SSH public key. You will also need to
|
||||
We now deploy the VPN with Terraform. Make sure that you are in the correct folder `terraform/deployment-nextcloud` with the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy the VPN:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
@@ -321,18 +321,18 @@ After deployments, take note of the 3nodes' IPv4 address. You will need those ad
|
||||
### SSH into the 3nodes
|
||||
|
||||
* To [SSH into the 3nodes](ssh_guide.md), write the following:
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_Address
|
||||
```
|
||||
|
||||
### Preparing the VMs for the Deployment
|
||||
|
||||
* Update and upgrade the system
|
||||
* ```
|
||||
```
|
||||
apt update && apt upgrade -y && apt-get install apache2 -y
|
||||
```
|
||||
* After download, reboot the system
|
||||
* ```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
* Reconnect to the VMs
|
||||
@@ -348,19 +348,19 @@ For more information on WireGuard, notably in relation to Windows, please read [
|
||||
First, we set Wireguard with the Terraform output.
|
||||
|
||||
* On your local computer, take the Terraform's `wg_config` output and create a `wg.conf` file in the directory `/etc/wireguard/wg.conf`.
|
||||
* ```
|
||||
```
|
||||
nano /etc/wireguard/wg.conf
|
||||
```
|
||||
|
||||
* Paste the content provided by the Terraform deployment. You can use `terraform show` to see the Terraform output. The Wireguard output stands in between `EOT`.
|
||||
|
||||
* Start Wireguard on your local computer:
|
||||
* ```
|
||||
```
|
||||
wg-quick up wg
|
||||
```
|
||||
|
||||
* To stop the wireguard service:
|
||||
* ```
|
||||
```
|
||||
wg-quick down wg
|
||||
```
|
||||
|
||||
@@ -368,10 +368,10 @@ If it doesn't work and you already did a wireguard connection with the same file
|
||||
This should set everything properly.
|
||||
|
||||
* As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the virtual IP addresses of both VMs to make sure the Wireguard connection is correct:
|
||||
* ```
|
||||
```
|
||||
ping 10.1.3.2
|
||||
```
|
||||
* ```
|
||||
```
|
||||
ping 10.1.4.2
|
||||
```
|
||||
|
||||
@@ -384,11 +384,11 @@ If you correctly receive the packets from the two VMs, you know that the VPN is
|
||||
## Download MariaDB and Configure the Database
|
||||
|
||||
* Download MariaDB's server and client on both VMs
|
||||
* ```
|
||||
```
|
||||
apt install mariadb-server mariadb-client -y
|
||||
```
|
||||
* Configure the MariaDB database
|
||||
* ```
|
||||
```
|
||||
nano /etc/mysql/mariadb.conf.d/50-server.cnf
|
||||
```
|
||||
* Do the following changes
|
||||
@@ -405,19 +405,19 @@ If you correctly receive the packets from the two VMs, you know that the VPN is
|
||||
```
|
||||
|
||||
* Restart MariaDB
|
||||
* ```
|
||||
```
|
||||
systemctl restart mysql
|
||||
```
|
||||
|
||||
* Launch MariaDB
|
||||
* ```
|
||||
```
|
||||
mysql
|
||||
```
|
||||
|
||||
## Create User with Replication Grant
|
||||
|
||||
* Do the following on both VMs
|
||||
* ```
|
||||
```
|
||||
CREATE USER 'repuser'@'%' IDENTIFIED BY 'password';
|
||||
GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'%' ;
|
||||
FLUSH PRIVILEGES;
|
||||
@@ -436,33 +436,33 @@ If you correctly receive the packets from the two VMs, you know that the VPN is
|
||||
### TF Template Worker Server Data
|
||||
|
||||
* Write the following in the worker VM
|
||||
* ```
|
||||
```
|
||||
CHANGE MASTER TO MASTER_HOST='10.1.3.2',
|
||||
MASTER_USER='repuser',
|
||||
MASTER_PASSWORD='password',
|
||||
MASTER_LOG_FILE='mysql-bin.000001',
|
||||
MASTER_LOG_POS=328;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
start slave;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
show slave status\G;
|
||||
```
|
||||
### TF Template Master Server Data
|
||||
|
||||
* Write the following in the master VM
|
||||
* ```
|
||||
```
|
||||
CHANGE MASTER TO MASTER_HOST='10.1.4.2',
|
||||
MASTER_USER='repuser',
|
||||
MASTER_PASSWORD='password',
|
||||
MASTER_LOG_FILE='mysql-bin.000001',
|
||||
MASTER_LOG_POS=328;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
start slave;
|
||||
```
|
||||
* ```
|
||||
```
|
||||
show slave status\G;
|
||||
```
|
||||
|
||||
@@ -505,72 +505,72 @@ We now set the Nextcloud database. You should choose your own username and passw
|
||||
We will now install and set [GlusterFS](https://www.gluster.org/), a free and open source software scalable network filesystem.
|
||||
|
||||
* Install GlusterFS on both the master and worker VMs
|
||||
* ```
|
||||
```
|
||||
echo | add-apt-repository ppa:gluster/glusterfs-7 && apt install glusterfs-server -y
|
||||
```
|
||||
* Start the GlusterFS service on both VMs
|
||||
* ```
|
||||
```
|
||||
systemctl start glusterd.service && systemctl enable glusterd.service
|
||||
```
|
||||
* Set the master to worker probe IP on the master VM:
|
||||
* ```
|
||||
```
|
||||
gluster peer probe 10.1.4.2
|
||||
```
|
||||
|
||||
* See the peer status on the worker VM:
|
||||
* ```
|
||||
```
|
||||
gluster peer status
|
||||
```
|
||||
|
||||
* Set the master and worker IP address on the master VM:
|
||||
* ```
|
||||
```
|
||||
gluster volume create vol1 replica 2 10.1.3.2:/gluster-storage 10.1.4.2:/gluster-storage force
|
||||
```
|
||||
|
||||
* Start GlusterFS on the master VM:
|
||||
* ```
|
||||
```
|
||||
gluster volume start vol1
|
||||
```
|
||||
|
||||
* Check the status on the worker VM:
|
||||
* ```
|
||||
```
|
||||
gluster volume status
|
||||
```
|
||||
|
||||
* Mount the server with the master IP on the master VM:
|
||||
* ```
|
||||
```
|
||||
mount -t glusterfs 10.1.3.2:/vol1 /var/www
|
||||
```
|
||||
|
||||
* See if the mount is there on the master VM:
|
||||
* ```
|
||||
```
|
||||
df -h
|
||||
```
|
||||
|
||||
* Mount the server with the worker IP on the worker VM:
|
||||
* ```
|
||||
```
|
||||
mount -t glusterfs 10.1.4.2:/vol1 /var/www
|
||||
```
|
||||
|
||||
* See if the mount is there on the worker VM:
|
||||
* ```
|
||||
```
|
||||
df -h
|
||||
```
|
||||
|
||||
We now update the mount with the filse fstab on both VMs.
|
||||
|
||||
* To prevent the mount from being aborted if the server reboots, write the following on both servers:
|
||||
* ```
|
||||
```
|
||||
nano /etc/fstab
|
||||
```
|
||||
|
||||
* Add the following line in the `fstab` file to set the master VM with the master virtual IP (here it is 10.1.3.2):
|
||||
* ```
|
||||
```
|
||||
10.1.3.2:/vol1 /var/www glusterfs defaults,_netdev 0 0
|
||||
```
|
||||
|
||||
* Add the following line in the `fstab` file to set the worker VM with the worker virtual IP (here it is 10.1.4.2):
|
||||
* ```
|
||||
```
|
||||
10.1.4.2:/vol1 /var/www glusterfs defaults,_netdev 0 0
|
||||
```
|
||||
|
||||
@@ -579,14 +579,14 @@ We now update the mount with the filse fstab on both VMs.
|
||||
# Install PHP and Nextcloud
|
||||
|
||||
* Install PHP and the PHP modules for Nextcloud on both the master and the worker:
|
||||
* ```
|
||||
```
|
||||
apt install php -y && apt-get install php zip libapache2-mod-php php-gd php-json php-mysql php-curl php-mbstring php-intl php-imagick php-xml php-zip php-mysql php-bcmath php-gmp zip -y
|
||||
```
|
||||
|
||||
We will now install Nextcloud. This is done only on the master VM.
|
||||
|
||||
* On both the master and worker VMs, go to the folder `/var/www`:
|
||||
* ```
|
||||
```
|
||||
cd /var/www
|
||||
```
|
||||
|
||||
@@ -594,27 +594,27 @@ We will now install Nextcloud. This is done only on the master VM.
|
||||
* See the latest [Nextcloud releases](https://download.nextcloud.com/server/releases/).
|
||||
|
||||
* We now download Nextcloud on the master VM.
|
||||
* ```
|
||||
```
|
||||
wget https://download.nextcloud.com/server/releases/nextcloud-27.0.1.zip
|
||||
```
|
||||
|
||||
You only need to download on the master VM, since you set a peer-to-peer connection, it will also be accessible on the worker VM.
|
||||
|
||||
* Then, extract the `.zip` file. This will take a couple of minutes. We use 7z to track progress:
|
||||
* ```
|
||||
```
|
||||
apt install p7zip-full -y
|
||||
```
|
||||
* ```
|
||||
```
|
||||
7z x nextcloud-27.0.1.zip -o/var/www/
|
||||
```
|
||||
|
||||
* After the download, see if the Nextcloud file is there on the worker VM:
|
||||
* ```
|
||||
```
|
||||
ls
|
||||
```
|
||||
|
||||
* Then, we grant permissions to the folder. Do this on both the master VM and the worker VM.
|
||||
* ```
|
||||
```
|
||||
chown www-data:www-data /var/www/nextcloud/ -R
|
||||
```
|
||||
|
||||
@@ -660,7 +660,7 @@ Note: When the master VM goes offline, after 5 minutes maximum DuckDNS will chan
|
||||
We now want to tell Apache where to store the Nextcloud data. To do this, we will create a file called `nextcloud.conf`.
|
||||
|
||||
* On both the master and worker VMs, write the following:
|
||||
* ```
|
||||
```
|
||||
nano /etc/apache2/sites-available/nextcloud.conf
|
||||
```
|
||||
|
||||
@@ -694,12 +694,12 @@ The file should look like this, with your own subdomain instead of `subdomain`:
|
||||
```
|
||||
|
||||
* On both the master VM and the worker VM, write the following to set the Nextcloud database with Apache and to enable the new virtual host file:
|
||||
* ```
|
||||
```
|
||||
a2ensite nextcloud.conf && a2enmod rewrite headers env dir mime setenvif ssl
|
||||
```
|
||||
|
||||
* Then, reload and restart Apache:
|
||||
* ```
|
||||
```
|
||||
systemctl reload apache2 && systemctl restart apache2
|
||||
```
|
||||
|
||||
@@ -710,20 +710,20 @@ The file should look like this, with your own subdomain instead of `subdomain`:
|
||||
We now access Nextcloud over the public Internet.
|
||||
|
||||
* Go to a web browser and write the subdomain name created with DuckDNS (adjust with your own subdomain):
|
||||
* ```
|
||||
```
|
||||
subdomain.duckdns.org
|
||||
```
|
||||
|
||||
Note: HTTPS isn't yet enabled. If you can't access the website, make sure to enable HTTP websites on your browser.
|
||||
|
||||
* Choose a name and a password. For this guide, we use the following:
|
||||
* ```
|
||||
```
|
||||
ncadmin
|
||||
password1234
|
||||
```
|
||||
|
||||
* Enter the Nextcloud Database information created with MariaDB and click install:
|
||||
* ```
|
||||
```
|
||||
Database user: ncuser
|
||||
Database password: password1234
|
||||
Database name: nextcloud
|
||||
@@ -749,27 +749,27 @@ To enable HTTPS, first install `letsencrypt` with `certbot`:
|
||||
Install certbot by following the steps here: [https://certbot.eff.org/](https://certbot.eff.org/)
|
||||
|
||||
* See if you have the latest version of snap:
|
||||
* ```
|
||||
```
|
||||
snap install core; snap refresh core
|
||||
```
|
||||
|
||||
* Remove certbot-auto:
|
||||
* ```
|
||||
```
|
||||
apt-get remove certbot
|
||||
```
|
||||
|
||||
* Install certbot:
|
||||
* ```
|
||||
```
|
||||
snap install --classic certbot
|
||||
```
|
||||
|
||||
* Ensure that certbot can be run:
|
||||
* ```
|
||||
```
|
||||
ln -s /snap/bin/certbot /usr/bin/certbot
|
||||
```
|
||||
|
||||
* Then, install certbot-apache:
|
||||
* ```
|
||||
```
|
||||
apt install python3-certbot-apache -y
|
||||
```
|
||||
|
||||
@@ -825,7 +825,7 @@ output "ipv4_vm1" {
|
||||
```
|
||||
|
||||
* To add the HTTPS protection, write the following line on the master VM with your own subdomain:
|
||||
* ```
|
||||
```
|
||||
certbot --apache -d subdomain.duckdns.org -d www.subdomain.duckdns.org
|
||||
```
|
||||
|
||||
@@ -837,7 +837,7 @@ Note: You then need to redo the same process with the worker VM. This time, make
|
||||
## Verify HTTPS Automatic Renewal
|
||||
|
||||
* Make a dry run of the certbot renewal to verify that it is correctly set up.
|
||||
* ```
|
||||
```
|
||||
certbot renew --dry-run
|
||||
```
|
||||
|
||||
@@ -859,25 +859,25 @@ We thus add the following rules:
|
||||
|
||||
|
||||
* Allow SSH (port 22)
|
||||
* ```
|
||||
```
|
||||
ufw allow ssh
|
||||
```
|
||||
* Allow HTTP (port 80)
|
||||
* ```
|
||||
```
|
||||
ufw allow http
|
||||
```
|
||||
* Allow https (port 443)
|
||||
* ```
|
||||
```
|
||||
ufw allow https
|
||||
```
|
||||
|
||||
* To enable the firewall, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
* To see the current security rules, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw status verbose
|
||||
```
|
||||
|
||||
|
||||
@@ -112,19 +112,19 @@ Modify the variable files to take into account your own seed phrase and SSH keys
|
||||
Open the terminal and follow those steps.
|
||||
|
||||
* Go to the home folder
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-single-nextcloud`:
|
||||
* ```
|
||||
```
|
||||
mkdir -p terraform/deployment-single-nextcloud
|
||||
```
|
||||
* ```
|
||||
```
|
||||
cd terraform/deployment-single-nextcloud
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -226,12 +226,12 @@ output "ipv4_vm1" {
|
||||
In this file, we name the full VM as `vm1`.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file.
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -249,12 +249,12 @@ Make sure to add your own seed phrase and SSH public key. You will also need to
|
||||
We now deploy the full VM with Terraform. Make sure that you are in the correct folder `terraform/deployment-single-nextcloud` with the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy the full VM:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
@@ -263,18 +263,18 @@ After deployments, take note of the 3Node's IPv4 address. You will need this add
|
||||
## SSH into the 3Node
|
||||
|
||||
* To [SSH into the 3Node](ssh_guide.md), write the following:
|
||||
* ```
|
||||
```
|
||||
ssh root@VM_IPv4_Address
|
||||
```
|
||||
|
||||
## Prepare the Full VM
|
||||
|
||||
* Update and upgrade the system
|
||||
* ```
|
||||
```
|
||||
apt update && apt upgrade && apt-get install apache2
|
||||
```
|
||||
* After download, reboot the system
|
||||
* ```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
* Reconnect to the VM
|
||||
@@ -286,11 +286,11 @@ After deployments, take note of the 3Node's IPv4 address. You will need this add
|
||||
## Download MariaDB and Configure the Database
|
||||
|
||||
* Download MariaDB's server and client
|
||||
* ```
|
||||
```
|
||||
apt install mariadb-server mariadb-client
|
||||
```
|
||||
* Configure the MariaDB database
|
||||
* ```
|
||||
```
|
||||
nano /etc/mysql/mariadb.conf.d/50-server.cnf
|
||||
```
|
||||
* Do the following changes
|
||||
@@ -307,12 +307,12 @@ After deployments, take note of the 3Node's IPv4 address. You will need this add
|
||||
```
|
||||
|
||||
* Restart MariaDB
|
||||
* ```
|
||||
```
|
||||
systemctl restart mysql
|
||||
```
|
||||
|
||||
* Launch MariaDB
|
||||
* ```
|
||||
```
|
||||
mysql
|
||||
```
|
||||
|
||||
@@ -345,14 +345,14 @@ We now set the Nextcloud database. You should choose your own username and passw
|
||||
# Install PHP and Nextcloud
|
||||
|
||||
* Install PHP and the PHP modules for Nextcloud on both the master and the worker:
|
||||
* ```
|
||||
```
|
||||
apt install php && apt-get install php zip libapache2-mod-php php-gd php-json php-mysql php-curl php-mbstring php-intl php-imagick php-xml php-zip php-mysql php-bcmath php-gmp zip
|
||||
```
|
||||
|
||||
We will now install Nextcloud.
|
||||
|
||||
* On the full VM, go to the folder `/var/www`:
|
||||
* ```
|
||||
```
|
||||
cd /var/www
|
||||
```
|
||||
|
||||
@@ -360,19 +360,17 @@ We will now install Nextcloud.
|
||||
* See the latest [Nextcloud releases](https://download.nextcloud.com/server/releases/).
|
||||
|
||||
* We now download Nextcloud on the full VM.
|
||||
* ```
|
||||
```
|
||||
wget https://download.nextcloud.com/server/releases/nextcloud-27.0.1.zip
|
||||
```
|
||||
|
||||
* Then, extract the `.zip` file. This will take a couple of minutes. We use 7z to track progress:
|
||||
* ```
|
||||
apt install p7zip-full
|
||||
```
|
||||
* ```
|
||||
apt install p7zip-full
|
||||
7z x nextcloud-27.0.1.zip -o/var/www/
|
||||
```
|
||||
* Then, we grant permissions to the folder.
|
||||
* ```
|
||||
```
|
||||
chown www-data:www-data /var/www/nextcloud/ -R
|
||||
```
|
||||
|
||||
@@ -398,7 +396,7 @@ Hint: make sure to save the DuckDNS folder in the home menu. Write `cd ~` before
|
||||
We now want to tell Apache where to store the Nextcloud data. To do this, we will create a file called `nextcloud.conf`.
|
||||
|
||||
* On full VM, write the following:
|
||||
* ```
|
||||
```
|
||||
nano /etc/apache2/sites-available/nextcloud.conf
|
||||
```
|
||||
|
||||
@@ -432,12 +430,12 @@ The file should look like this, with your own subdomain instead of `subdomain`:
|
||||
```
|
||||
|
||||
* On the full VM, write the following to set the Nextcloud database with Apache and to enable the new virtual host file:
|
||||
* ```
|
||||
```
|
||||
a2ensite nextcloud.conf && a2enmod rewrite headers env dir mime setenvif ssl
|
||||
```
|
||||
|
||||
* Then, reload and restart Apache:
|
||||
* ```
|
||||
```
|
||||
systemctl reload apache2 && systemctl restart apache2
|
||||
```
|
||||
|
||||
@@ -448,20 +446,20 @@ The file should look like this, with your own subdomain instead of `subdomain`:
|
||||
We now access Nextcloud over the public Internet.
|
||||
|
||||
* Go to a web browser and write the subdomain name created with DuckDNS (adjust with your own subdomain):
|
||||
* ```
|
||||
```
|
||||
subdomain.duckdns.org
|
||||
```
|
||||
|
||||
Note: HTTPS isn't yet enabled. If you can't access the website, make sure to enable HTTP websites on your browser.
|
||||
|
||||
* Choose a name and a password. For this guide, we use the following:
|
||||
* ```
|
||||
```
|
||||
ncadmin
|
||||
password1234
|
||||
```
|
||||
|
||||
* Enter the Nextcloud Database information created with MariaDB and click install:
|
||||
* ```
|
||||
```
|
||||
Database user: ncuser
|
||||
Database password: password1234
|
||||
Database name: nextcloud
|
||||
@@ -487,27 +485,27 @@ To enable HTTPS, first install `letsencrypt` with `certbot`:
|
||||
Install certbot by following the steps here: [https://certbot.eff.org/](https://certbot.eff.org/)
|
||||
|
||||
* See if you have the latest version of snap:
|
||||
* ```
|
||||
```
|
||||
snap install core; snap refresh core
|
||||
```
|
||||
|
||||
* Remove certbot-auto:
|
||||
* ```
|
||||
```
|
||||
apt-get remove certbot
|
||||
```
|
||||
|
||||
* Install certbot:
|
||||
* ```
|
||||
```
|
||||
snap install --classic certbot
|
||||
```
|
||||
|
||||
* Ensure that certbot can be run:
|
||||
* ```
|
||||
```
|
||||
ln -s /snap/bin/certbot /usr/bin/certbot
|
||||
```
|
||||
|
||||
* Then, install certbot-apache:
|
||||
* ```
|
||||
```
|
||||
apt install python3-certbot-apache
|
||||
```
|
||||
|
||||
@@ -516,14 +514,14 @@ Install certbot by following the steps here: [https://certbot.eff.org/](https://
|
||||
We now set the certbot with the DNS domain.
|
||||
|
||||
* To add the HTTPS protection, write the following line on the full VM with your own subdomain:
|
||||
* ```
|
||||
```
|
||||
certbot --apache -d subdomain.duckdns.org -d www.subdomain.duckdns.org
|
||||
```
|
||||
|
||||
## Verify HTTPS Automatic Renewal
|
||||
|
||||
* Make a dry run of the certbot renewal to verify that it is correctly set up.
|
||||
* ```
|
||||
```
|
||||
certbot renew --dry-run
|
||||
```
|
||||
|
||||
@@ -545,25 +543,25 @@ We thus add the following rules:
|
||||
|
||||
|
||||
* Allow SSH (port 22)
|
||||
* ```
|
||||
```
|
||||
ufw allow ssh
|
||||
```
|
||||
* Allow HTTP (port 80)
|
||||
* ```
|
||||
```
|
||||
ufw allow http
|
||||
```
|
||||
* Allow https (port 443)
|
||||
* ```
|
||||
```
|
||||
ufw allow https
|
||||
```
|
||||
|
||||
* To enable the firewall, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
* To see the current security rules, write the following:
|
||||
* ```
|
||||
```
|
||||
ufw status verbose
|
||||
```
|
||||
|
||||
|
||||
@@ -246,17 +246,17 @@ output "fqdn" {
|
||||
We now deploy the 2-node VPN with Terraform. Make sure that you are in the correct folder containing the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy Nextcloud:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
Note that, at any moment, if you want to see the information on your Terraform deployment, write the following:
|
||||
* ```
|
||||
```
|
||||
terraform show
|
||||
```
|
||||
|
||||
@@ -274,40 +274,42 @@ Note that, at any moment, if you want to see the information on your Terraform d
|
||||
We need to install a few things on the Nextcloud VM before going further.
|
||||
|
||||
* Update the Nextcloud VM
|
||||
* ```
|
||||
```
|
||||
apt update
|
||||
```
|
||||
* Install ping on the Nextcloud VM if you want to test the VPN connection (Optional)
|
||||
* ```
|
||||
```
|
||||
apt install iputils-ping -y
|
||||
```
|
||||
* Install Rsync on the Nextcloud VM
|
||||
* ```
|
||||
```
|
||||
apt install rsync
|
||||
```
|
||||
* Install nano on the Nextcloud VM
|
||||
* ```
|
||||
```
|
||||
apt install nano
|
||||
```
|
||||
* Install Cron on the Nextcloud VM
|
||||
* apt install cron
|
||||
```
|
||||
apt install cron
|
||||
```
|
||||
|
||||
# Prepare the VMs for the Rsync Daily Backup
|
||||
|
||||
* Test the VPN (Optional) with [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping)
|
||||
* ```
|
||||
```
|
||||
ping <WireGuard_VM_IP_Address>
|
||||
```
|
||||
* Generate an SSH key pair on the Backup VM
|
||||
* ```
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
* Take note of the public key in the Backup VM
|
||||
* ```
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
```
|
||||
* Add the public key of the Backup VM in the Nextcloud VM
|
||||
* ```
|
||||
```
|
||||
nano ~/.ssh/authorized_keys
|
||||
```
|
||||
|
||||
@@ -318,11 +320,11 @@ We need to install a few things on the Nextcloud VM before going further.
|
||||
We now set a daily cron job that will make a backup between the Nextcloud VM and the Backup VM using Rsync.
|
||||
|
||||
* Open the crontab on the Backup VM
|
||||
* ```
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
* Add the cron job at the end of the file
|
||||
* ```
|
||||
```
|
||||
0 8 * * * rsync -avz --no-perms -O --progress --delete --log-file=/root/rsync_storage.log root@10.1.3.2:/mnt/backup/ /mnt/backup/
|
||||
```
|
||||
|
||||
|
||||
@@ -61,14 +61,14 @@ Also note that this deployment uses both the Planetary network and WireGuard.
|
||||
We start by creating the main file for our Nomad cluster.
|
||||
|
||||
* Create a directory for your Terraform Nomad cluster
|
||||
* ```
|
||||
```
|
||||
mkdir nomad
|
||||
```
|
||||
* ```
|
||||
```
|
||||
cd nomad
|
||||
```
|
||||
* Create the `main.tf` file
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -255,12 +255,12 @@ output "client2_planetary_ip" {
|
||||
We create a credentials file that will contain the environment variables. This file should be in the same directory as the main file.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -280,12 +280,12 @@ Make sure to replace the three dots by your own information for `mnemonics` and
|
||||
We now deploy the Nomad Cluster with Terraform. Make sure that you are in the directory containing the `main.tf` file.
|
||||
|
||||
* Initialize Terraform
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy the Nomad cluster
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
@@ -300,7 +300,7 @@ Note that the IP addresses will be shown under `Outputs` after running the comma
|
||||
### SSH with the Planetary Network
|
||||
|
||||
* To [SSH with the Planetary network](ssh_openssh.md), write the following with the proper IP address
|
||||
* ```
|
||||
```
|
||||
ssh root@planetary_ip
|
||||
```
|
||||
|
||||
@@ -311,7 +311,7 @@ You now have an SSH connection access over the Planetary network to the client a
|
||||
To SSH with WireGuard, we first need to set the proper WireGuard configurations.
|
||||
|
||||
* Create a file named `wg.conf` in the directory `/etc/wireguard`
|
||||
* ```
|
||||
```
|
||||
nano /etc/wireguard/wg.conf
|
||||
```
|
||||
|
||||
@@ -319,18 +319,18 @@ To SSH with WireGuard, we first need to set the proper WireGuard configurations.
|
||||
* Note that you can use `terraform show` to see the Terraform output. The WireGuard configurations (`wg_config`) stands in between the two `EOT` instances.
|
||||
|
||||
* Start WireGuard on your local computer
|
||||
* ```
|
||||
```
|
||||
wg-quick up wg
|
||||
```
|
||||
* As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the WireGuard IP of a node to make sure the connection is correct
|
||||
* ```
|
||||
```
|
||||
ping wg_ip
|
||||
```
|
||||
|
||||
We are now ready to SSH into the client and server nodes with WireGuard.
|
||||
|
||||
* To SSH with WireGuard, write the following with the proper IP address:
|
||||
* ```
|
||||
```
|
||||
ssh root@wg_ip
|
||||
```
|
||||
|
||||
|
||||
@@ -70,20 +70,19 @@ Modify the variable file to take into account your own seed phras and SSH keys.
|
||||
Now let's create the Terraform files.
|
||||
|
||||
* Open the terminal and go to the home directory
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-wg-ssh`:
|
||||
* ```
|
||||
```
|
||||
mkdir -p terraform/deployment-wg-ssh
|
||||
```
|
||||
* ```
|
||||
```
|
||||
cd terraform/deployment-wg-ssh
|
||||
```
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -173,12 +172,12 @@ output "node1_zmachine1_ip" {
|
||||
```
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content, set the node ID as well as your mnemonics and SSH public key, then save the file.
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -198,12 +197,12 @@ Make sure to add your own seed phrase and SSH public key. You will also need to
|
||||
We now deploy the micro VM with Terraform. Make sure that you are in the correct folder `terraform/deployment-wg-ssh` containing the main and variables files.
|
||||
|
||||
* Initialize Terraform:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
* Apply Terraform to deploy the micro VM:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
* Terraform will then present you the actions it will perform. Write `yes` to confirm the deployment.
|
||||
@@ -264,10 +263,11 @@ You now have access into the VM over Wireguard SSH connection.
|
||||
|
||||
If you want to destroy the Terraform deployment, write the following in the terminal:
|
||||
|
||||
* ```
|
||||
```
|
||||
terraform destroy
|
||||
```
|
||||
* Then write `yes` to confirm.
|
||||
|
||||
Then write `yes` to confirm.
|
||||
|
||||
Make sure that you are in the corresponding Terraform folder when writing this command. In this guide, the folder is `deployment-wg-ssh`.
|
||||
|
||||
|
||||
@@ -74,19 +74,19 @@ Now let's create the Terraform files.
|
||||
|
||||
|
||||
* Open the terminal and go to the home directory
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-wg-vpn`:
|
||||
* ```
|
||||
```
|
||||
mkdir -p terraform && cd $_
|
||||
```
|
||||
* ```
|
||||
```
|
||||
mkdir deployment-wg-vpn && cd $_
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -229,12 +229,12 @@ output "ipv4_vm2" {
|
||||
In this guide, the virtual IP for `vm1` is 10.1.3.2 and the virtual IP for `vm2` is 10.1.4.2. This might be different during your own deployment. Change the codes in this guide accordingly.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file.
|
||||
* ```
|
||||
```
|
||||
mnemonics = "..."
|
||||
SSH_KEY = "..."
|
||||
|
||||
@@ -256,17 +256,17 @@ Set the parameters for your VMs as you wish. The two servers will have the same
|
||||
We now deploy the VPN with Terraform. Make sure that you are in the correct folder `terraform/deployment-wg-vpn` containing the main and variables files.
|
||||
|
||||
* Initialize Terraform by writing the following in the terminal:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
* Apply the Terraform deployment:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
* Terraform will then present you the actions it will perform. Write `yes` to confirm the deployment.
|
||||
|
||||
Note that, at any moment, if you want to see the information on your Terraform deployments, write the following:
|
||||
* ```
|
||||
```
|
||||
terraform show
|
||||
```
|
||||
|
||||
@@ -279,19 +279,19 @@ To set the Wireguard connection, on your local computer, you will need to take t
|
||||
For more information on WireGuard, notably in relation to Windows, please read [this documentation](ssh_wireguard.md).
|
||||
|
||||
* Create a file named `wg.conf` in the directory: `/usr/local/etc/wireguard/wg.conf`.
|
||||
* ```
|
||||
```
|
||||
nano /usr/local/etc/wireguard/wg.conf
|
||||
```
|
||||
* Paste the content between the two `EOT` displayed after you set `terraform apply`.
|
||||
|
||||
* Start the wireguard:
|
||||
* ```
|
||||
```
|
||||
wg-quick up wg
|
||||
```
|
||||
|
||||
If you want to stop the Wireguard service, write the following on your terminal:
|
||||
|
||||
* ```
|
||||
```
|
||||
wg-quick down wg
|
||||
```
|
||||
|
||||
@@ -299,7 +299,7 @@ If you want to stop the Wireguard service, write the following on your terminal:
|
||||
|
||||
As a test, you can [ping](../../computer_it_basics/cli_scripts_basics.md#test-the-network-connectivity-of-a-domain-or-an-ip-address-with-ping) the virtual IP address of the VMs to make sure the Wireguard connection is correct. Make sure to replace `wg_vm_ip` with the proper IP address for each VM:
|
||||
|
||||
* ```
|
||||
```
|
||||
ping wg_vm_ip
|
||||
```
|
||||
|
||||
@@ -329,10 +329,11 @@ You now have an SSH connection access to the VMs over Wireguard and IPv4.
|
||||
|
||||
If you want to destroy the Terraform deployment, write the following in the terminal:
|
||||
|
||||
* ```
|
||||
```
|
||||
terraform destroy
|
||||
```
|
||||
* Then write `yes` to confirm.
|
||||
|
||||
Then write `yes` to confirm.
|
||||
|
||||
Make sure that you are in the corresponding Terraform folder when writing this command. In this guide, the folder is `deployment-wg-vpn`.
|
||||
|
||||
|
||||
@@ -65,31 +65,31 @@ We present two different methods to create the Terraform files. In the first met
|
||||
Creating the Terraform files is very straightforward. We want to clone the repository `terraform-provider-grid` locally and run some simple commands to properly set and start the deployment.
|
||||
|
||||
* Clone the repository `terraform-provider-grid`
|
||||
* ```
|
||||
```
|
||||
git clone https://github.com/threefoldtech/terraform-provider-grid
|
||||
```
|
||||
* Go to the subdirectory containing the examples
|
||||
* ```
|
||||
```
|
||||
cd terraform-provider-grid/examples/resources/qsfs
|
||||
```
|
||||
* Set your own mnemonics (replace `mnemonics words` with your own mnemonics)
|
||||
* ```
|
||||
```
|
||||
export MNEMONICS="mnemonics words"
|
||||
```
|
||||
* Set the network (replace `network` by the desired network, e.g. `dev`, `qa`, `test` or `main`)
|
||||
* ```
|
||||
```
|
||||
export NETWORK="network"
|
||||
```
|
||||
* Initialize the Terraform deployment
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
* Apply the Terraform deployment
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
* At any moment, you can destroy the deployment with the following line
|
||||
* ```
|
||||
```
|
||||
terraform destroy
|
||||
```
|
||||
|
||||
@@ -100,21 +100,21 @@ When using this method, you might need to change some parameters within the `mai
|
||||
For this method, we use two files to deploy with Terraform. The first file contains the environment variables (**credentials.auto.tfvars**) and the second file contains the parameters to deploy our workloads (**main.tf**). To facilitate the deployment, only the environment variables file needs to be adjusted. The **main.tf** file contains the environment variables (e.g. `var.size` for the disk size) and thus you do not need to change this file, but only the file **credentials.auto.tfvars**.
|
||||
|
||||
* Open the terminal and go to the home directory (optional)
|
||||
* ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
* Create the folder `terraform` and the subfolder `deployment-qsfs-microvm`:
|
||||
* ```
|
||||
mkdir -p terraform && cd $_
|
||||
```
|
||||
* ```
|
||||
mkdir deployment-qsfs-microvm && cd $_
|
||||
```
|
||||
```
|
||||
mkdir -p terraform && cd $_
|
||||
```
|
||||
```
|
||||
mkdir deployment-qsfs-microvm && cd $_
|
||||
```
|
||||
* Create the `main.tf` file:
|
||||
* ```
|
||||
nano main.tf
|
||||
```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
* Copy the `main.tf` content and save the file.
|
||||
|
||||
@@ -274,12 +274,12 @@ output "ygg_ip" {
|
||||
Note that we named the VM as **vm1**.
|
||||
|
||||
* Create the `credentials.auto.tfvars` file:
|
||||
* ```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
* Copy the `credentials.auto.tfvars` content and save the file.
|
||||
* ```terraform
|
||||
```terraform
|
||||
# Network
|
||||
network = "main"
|
||||
|
||||
@@ -311,17 +311,17 @@ For the section QSFS Parameters, you can decide on how many VMs your data will b
|
||||
We now deploy the QSFS deployment with Terraform. Make sure that you are in the correct folder `terraform/deployment-qsfs-microvm` containing the main and variables files.
|
||||
|
||||
* Initialize Terraform by writing the following in the terminal:
|
||||
* ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
* Apply the Terraform deployment:
|
||||
* ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
* Terraform will then present you the actions it will perform. Write `yes` to confirm the deployment.
|
||||
|
||||
Note that, at any moment, if you want to see the information on your Terraform deployments, write the following:
|
||||
* ```
|
||||
```
|
||||
terraform show
|
||||
```
|
||||
|
||||
|
||||
@@ -59,15 +59,15 @@ There are two options when it comes to finding a node to deploy on. You can use
|
||||
We cover the basic preparations beforing explaining the main file.
|
||||
|
||||
- Make a directory for your project
|
||||
- ```
|
||||
```
|
||||
mkdir myfirstproject
|
||||
```
|
||||
- Change directory
|
||||
- ```
|
||||
```
|
||||
cd myfirstproject
|
||||
```
|
||||
- Create a main file and insert content
|
||||
- ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -109,11 +109,11 @@ provider "grid" {
|
||||
When writing the main file, you can decide to leave a variable content empty. In this case you can export the variable content as environment variables.
|
||||
|
||||
* Export your mnemonics
|
||||
* ```
|
||||
```
|
||||
export MNEMONICS="..."
|
||||
```
|
||||
* Export the network
|
||||
* ```
|
||||
```
|
||||
export NETWORK="..."
|
||||
```
|
||||
|
||||
|
||||
@@ -94,20 +94,20 @@ Open the terminal.
|
||||
|
||||
- Go to the home folder
|
||||
|
||||
- ```
|
||||
```
|
||||
cd ~
|
||||
```
|
||||
|
||||
- Create the folder `terraform` and the subfolder `deployment-full-vm`:
|
||||
- ```
|
||||
```
|
||||
mkdir -p terraform/deployment-full-vm
|
||||
```
|
||||
- ```
|
||||
```
|
||||
cd terraform/deployment-full-vm
|
||||
```
|
||||
- Create the `main.tf` file:
|
||||
|
||||
- ```
|
||||
```
|
||||
nano main.tf
|
||||
```
|
||||
|
||||
@@ -210,7 +210,7 @@ In this file, we name the VM as `vm1`.
|
||||
|
||||
- Create the `credentials.auto.tfvars` file:
|
||||
|
||||
- ```
|
||||
```
|
||||
nano credentials.auto.tfvars
|
||||
```
|
||||
|
||||
@@ -239,12 +239,12 @@ We now deploy the full VM with Terraform. Make sure that you are in the correct
|
||||
|
||||
- Initialize Terraform:
|
||||
|
||||
- ```
|
||||
```
|
||||
terraform init
|
||||
```
|
||||
|
||||
- Apply Terraform to deploy the full VM:
|
||||
- ```
|
||||
```
|
||||
terraform apply
|
||||
```
|
||||
|
||||
@@ -255,7 +255,7 @@ After deployments, take note of the 3Node' IPv4 address. You will need this addr
|
||||
## SSH into the 3Node
|
||||
|
||||
- To [SSH into the 3Node](ssh_guide.md), write the following:
|
||||
- ```
|
||||
```
|
||||
ssh root@VM_IPv4_Address
|
||||
```
|
||||
|
||||
|
||||
@@ -36,15 +36,15 @@ TFT lives on 4 different chains: TFChain, Stellar chain, Ethereum chain and Bina
|
||||
The TFT contract address on different chains are the following:
|
||||
|
||||
- [TFT Contract address on Stellar](https://stellarchain.io/assets/TFT-GBOVQKJYHXRR3DX6NOX2RRYFRCUMSADGDESTDNBDS6CDVLGVESRTAC47)
|
||||
- ```
|
||||
```
|
||||
TFT-GBOVQKJYHXRR3DX6NOX2RRYFRCUMSADGDESTDNBDS6CDVLGVESRTAC47
|
||||
```
|
||||
- [TFT Contract address on Ethereum](https://etherscan.io/token/0x395E925834996e558bdeC77CD648435d620AfB5b)
|
||||
- ```
|
||||
```
|
||||
0x395E925834996e558bdeC77CD648435d620AfB5b
|
||||
```
|
||||
- [TFT Contract address on BSC](https://bscscan.com/address/0x8f0FB159380176D324542b3a7933F0C2Fd0c2bbf)
|
||||
- ```
|
||||
```
|
||||
0x8f0FB159380176D324542b3a7933F0C2Fd0c2bbf
|
||||
```
|
||||
|
||||
|
||||
Reference in New Issue
Block a user